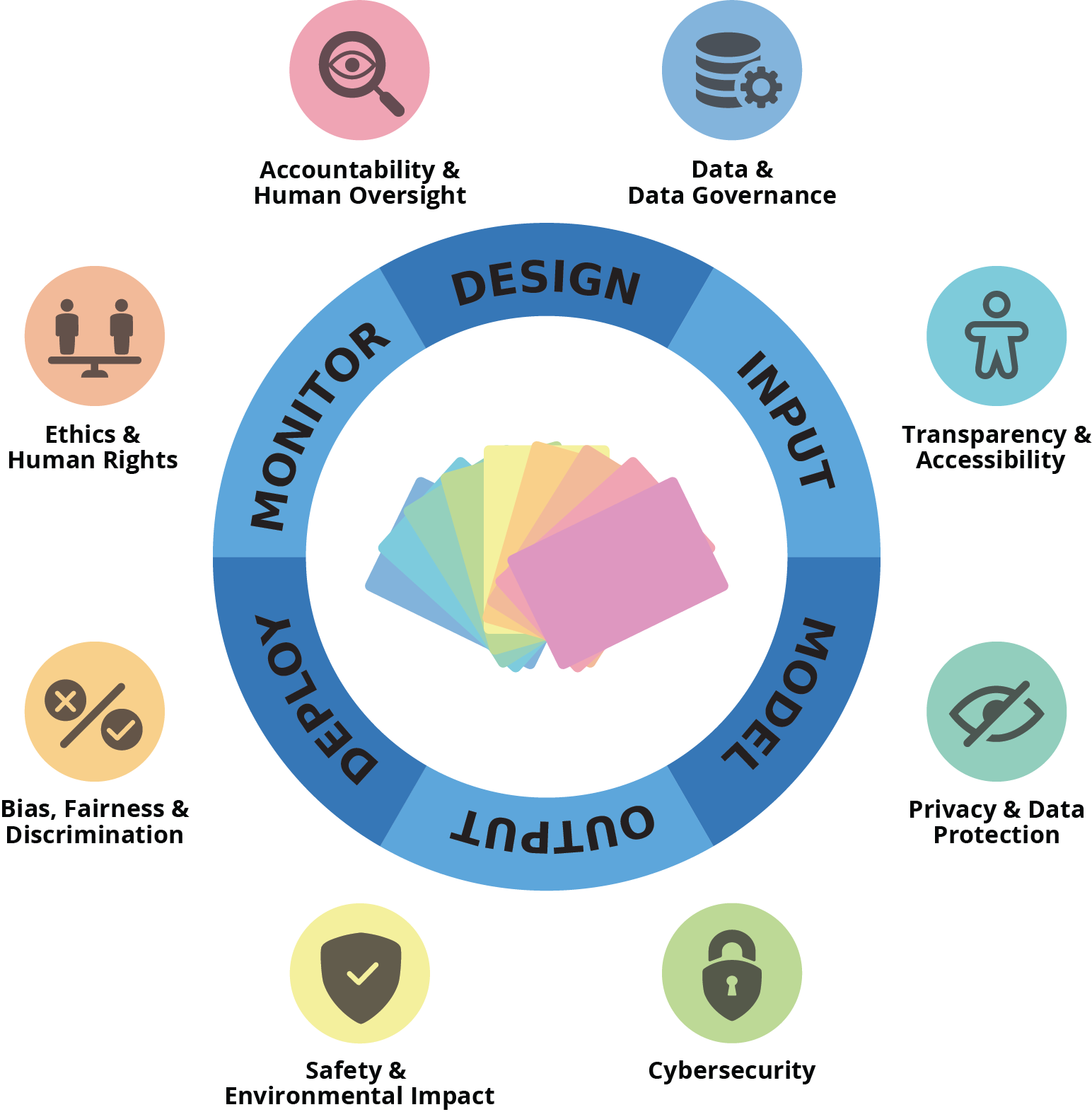
PLOT4AI is a library (currently) containing 138 threats related to AI/ML. The threats have been classified in 8 different categories.
In case you are new to PLOT4AI, read the HOW TO first.
Threat Modeling Categories
Click on a category to filter the cards below.
All
Data & Data Governance
Transparency & Accessibility
Privacy & Data Protection
Cybersecurity
Safety & Environmental Impact
Bias, Fairness & Discrimination
Ethics & Human Rights
Accountability & Human Oversight
Click on a card to view the contents; Then click on to flip it and see the backside of the card
(Please note: these cards can also be downloaded as CSV or PDF for offline usage)
Is our data complete, up-to-date, and trustworthy?
Can we prevent target leakage?
Can we prevent concept and data drift?
Can the AI model maintain continuous access to data sources after deployment?
Can we process new or updated data from external sources without delay?
Are all required data sources legitimate, authorized, and verified?
Can we obtain the data needed to develop or fine-tune the AI model?
Can we trace the provenance and lineage of the data used to train or fine-tune the AI model?
Could our dataset have copyright or other legal restrictions?
Can we detect and prevent data tampering across the AI lifecycle?
Does the AI system need to be explainable for users or affected persons?
Is our AI system inclusive and accessible?
If users’ consent is required, is the necessary information provided in a clear and accessible way?
Could the user perceive the message from the AI system in a different way than intended?
Is the AI system easy for users to learn and operate?
Are users clearly made aware that they are interacting with an AI system or consuming AI-generated content?
Are users informed about the AI system's reliability, limitations, and risks in a way that enables safe and effective use?
Can the training data be linked to individuals?
Could the AI system infer and reveal information that a person has not explicitly shared?
Could geolocation restrictions or regional regulations impact the implementation of our AI system in other countries?
Can we minimize the amount of personal data used while preserving model performance?
Are we processing special categories of personal data or sensitive data?
Could the AI system make decisions with legal or similarly significant effects without human intervention?
Do we have a valid legal basis for processing personal data?
Could we be using personal data for purposes different from those for which it was originally collected?
Are we able to comply with all the applicable GDPR data subjects’ rights?
Could we be deploying the AI system without conducting a required Data Protection Impact Assessment (DPIA)?
Are we using third-party providers while processing data from children or other vulnerable individuals?
Are we using metadata that could reveal personal data or behavior patterns?
Could we compromise users’ rights to privacy and to a private and family life?
Are we providing sufficient transparency about how the AI model collects, processes, and uses personal data?
Are we logging or storing user input data in ways that may violate privacy?
Could the AI system produce inaccurate or misleading outputs that result in privacy violations or harm?
Are we transferring personal data to countries that lack adequate privacy protections?
Can we comply with the storage limitation principle and international data retention regulations?
Could we be deploying the AI system without testing for adversarial robustness and systemic vulnerabilities?
Are our AI inference APIs and function-calling interfaces securely implemented?
Are training data, model output, and other sensitive AI assets securely stored?
If the AI system uses randomness, is the source of randomness properly protected?
Is the AI model suited for processing confidential information?
Have we implemented safeguards to detect and prevent insider threats to our AI systems?
Have we protected our AI system against model sabotage?
Is our AI model resilient to evasion attacks?
Are we protected from poisoning attacks?
Are we protected from model inversion attacks?
Are we protected from membership inference attacks?
Are we protected from model stealing attacks?
Are we protected from reprogramming deep neural nets attacks?
Are we protected from adversarial examples?
Could third-party AI/ML providers compromise our training data or insert backdoors?
Could the AI system be vulnerable to jailbreak techniques, allowing attackers to bypass safety restrictions?
Could the AI system be vulnerable to prompt injection attacks, leading to unauthorized access or manipulation?
Is the AI training environment secured against unauthorized access and manipulation?
Is the deployed AI system protected from unauthorized access and misuse?
Could third-party tools, plugins, or dependencies introduce vulnerabilities in our AI system?
Could the AI system generate or execute unsafe SQL queries from user input?
Could the AI system generate or execute unsafe code based on user input?
Could autonomous AI agents access or interact with malicious web content?
Could agent memory be poisoned with malicious or misleading information?
Could agents misuse tools or APIs they are authorized to access?
Could hallucinated output from one agent propagate and mislead others in multi-agent systems?
Can we trace and audit the actions and decisions of autonomous agents in our system?
Could a compromised or malicious agent sabotage a multi-agent system?
Could an agent gain access to functions or data beyond its intended permissions?
Could an attacker or user intentionally overload the AI system’s resources to degrade performance or cause failures?
Could an attacker or agent impersonate a user or AI identity to gain unauthorized influence?
Could an agent be misused to manipulate or deceive users?
Could an attacker intercept or manipulate communications between agents to alter system behavior?
Could unsafe file uploads introduce security risks?
Could unsafe deserialization of model artifacts lead to code execution or system compromise?
Could malicious fine-tuning compromise the safety or alignment of our GenAI model?
Are we protected from vulnerabilities in vector databases and RAG pipelines?
Could failures in real-time data collection channels disrupt model performance?
Could AI-generated hallucinations lead to misinformation or decision-making risks?
Could the lack of interpretability in our AI models compromise safety?
Can human over-reliance on automated systems lead to failures during emergencies?
Could performance or reliability issues emerge when scaling the AI system across environments?
In case of system failure, could users be adversely impacted?
Is our AI model robust and suitable for its intended use across different deployment contexts?
Could the AI system's performance on benchmarks be misleading or fail to reflect real-world risks?
Could the AI system become persuasive causing harm to users?
Could our AI agents hack their reward functions to exploit the system?
Could the AI system expose children to harmful, inappropriate, or unsafe content or interactions?
Could the AI system be misused for malicious purposes such as disinformation, cyberattacks or warfare?
Could the AI system accelerate the development of bioweapons or other CBRNE threats?
Could the AI system generate or disseminate deepfakes or synthetic media that mislead users, impersonate individuals, or cause harm?
Could the AI system generate toxic or harmful content?
Could the AI system deliberately mislead users or hide its capabilities during deployment or evaluation?
Could AI decisions result in physical damage, infrastructure failure, or major financial losses?
Do we monitor how version updates from third-party GenAI models can affect our system's behaviour?
Could the development of autonomous AI agents lead to loss of control, concentration of power or rogue behavior?
Could environmental phenomena or natural disasters compromise our AI system?
Could AI agents take actions that unintentionally harm users, the environment or themselves during learning or deployment?
Does training and deploying our AI system generate high CO2 emissions?
Could unsustainable data center cooling practices increase the environmental impact of our AI system?
Is the production of our AI hardware exploiting limited material resources?
Are we assessing our AI system’s environmental impact across its entire life cycle?
Is the dataset representative of the different real-world groups, populations and environments?
Could the AI system incorrectly attribute actions to individuals or groups?
Could certain groups be disproportionately affected by the outcomes of the AI system?
Could our AI system reinforce systemic inequalities?
Could our AI system oversimplify real-world problems?
Could our AI system accurately capture the factors it's designed to measure?
Could the AI system reinforce historical inequalities embedded in the data?
Can data be labeled consistently?
Could the system be using proxy variables that reflect sensitive attributes or lead to indirect discrimination?
Could the AI system’s design choices lead to unfair outcomes?
Could we over-rely on early evaluation results or AI-generated outputs?
Could popularity bias reduce diversity in system's recommendations?
Is the AI system designed to support multiple viewpoints and narratives?
Could our AI system contribute to social division or rivalry?
Could our AI system automatically label or categorize people?
Could the AI system affect employment conditions, labor rights, or job opportunities?
Could our AI system fail to uphold and respect human dignity?
Could the AI system affect democracy or have an adverse impact on society at large?
Do we offer users and accessible way to contest AI decisions or seek redress?
Could the system have an impact on decisions that affect life, health, or personal safety?
Could the AI system limit, suppress or distort users’ freedom of expression?
Could our AI system affect access to services such as healthcare, housing, insurance, benefits or education?
Could the AI system interfere with users’ autonomy influencing their decision-making process?
Could the AI system promote certain values or beliefs on users?
Could the AI system negatively impact vulnerable groups or fail to protect their rights?
Could the AI system fail to uphold the rights and best interests of children?
Is the development and use of the AI system proportionate to its intended purpose and impact on rights?
Does the AI system use behavioral data in ways that may raise ethical, privacy, or human rights concerns?
Is the AI system's task clearly defined, with well-scoped objectives and boundaries?
Have we identified and involved all key stakeholders relevant to this phase of the AI lifecycle?
Have all relevant staff and users received adequate training to understand, oversee, and responsibly interact with the AI system?
Do we have qualified people available to supervise the behavior of AI agents and provide feedback during learning?
Do we have the resources and processes to effectively oversee AI decision-making?
Is there a well-defined process to escalate AI-related failures or unexpected outcomes?
Have we defined who is accountable for the AI system’s decisions and outcomes?
Do we regularly review whether the AI system’s goals, assumptions, and impacts are still appropriate?
Can human operators safely interrupt or override the AI system at any time?
Could users contest or challenge the decisions made by the AI system?
Have we assessed our legal liability for damages caused by our AI system?
Do we have adequate resources and MLOps practices in place to manage, monitor, and maintain our AI system?
If we plan to deploy a third-party AI tool, have we assessed our shared responsibility for its potential impact on users?
I have created an overview of all the sources I have used for the creation of this library, which can be found under References
Data Quality
Is our data complete, up-to-date, and trustworthy?
Can you avoid the known principle of “garbage in, garbage out”? Your AI system is only as reliable as the data it works with.
If your answer is No or MAYBE, you might be at risk
FLIPCARD
Recommendations
Verify the data sources:
Is there information missing within the dataset?
Can we verify that our training and input data hasn’t been tampered with or corrupted?
Are we using datasets that are outdated or no longer reflect the current environment?
Are all the necessary classes represented?
Does the data belong to the correct time frame and geographical coverage?
Evaluate which extra data you need to collect/receive.
Carefully consider representation schemes, especially in cases of text, video, APIs, and sensors. Text representation schemes are not all the same. If your system is counting on ASCII and it gets Unicode, will your system recognize the incorrect encoding? Source: BerryVilleiML
Target Leakage
Can we prevent target leakage?
Target Leakage is present when your features contain information that your model should not legitimately be allowed to use, leading to overestimation of the model's performance. It can occur when information from outside the training dataset is improperly included in the model during training. This can result in an unrealistically high performance during evaluation.
If your answer is No or MAYBE, you might be at risk
FLIPCARD
Recommendations
Avoid using proxies for the outcome variable as a feature.
Do not use the entire data set for imputations, data-based transformations or feature selection.
Avoid doing standard k-fold cross-validation when you have temporal data.
Avoid using data that happened before model training time but is not available until later. This is common where there is delay in data collection.
Do not use data in the training set based on information from the future: if X happened after Y, you shouldn’t build a model that uses X to predict Y.
Data drift weakens performance because the model receives data on which it hasn’t been trained. It causes changes in the statistical properties of the input data distribution (e.g., feature distributions shift over time).
With Concept drift, the statistical properties of the target variable, which the model is trying to predict, change over time in unforeseen ways causing accuracy issues. It causes changes in the relationship between input features and the target variable (e.g., customer behavior changes over time, impacting a predictive model).
If your answer is No or MAYBE, you might be at risk
FLIPCARD
Recommendations
Implement robust monitoring tools to detect data and concept drift, and establish governance policies for regular data validation and model retraining.
Select an appropriate drift detection algorithm and apply it separately to labels, model’s predictions and data features.
Can the AI model maintain continuous access to data sources after deployment?
Will you use the output from other models to feed your model again (looping)? Or will you use other sources?
Your AI system may rely on internal pipelines or third-party data sources. If any of these become unavailable, the model may stop functioning or deliver inaccurate results.
This includes scenarios like discontinued APIs, broken survey collection tools, or changes in upstream system outputs.
If your answer is No or MAYBE, you might be at risk
FLIPCARD
Recommendations
Consider how the model will keep learning.
Identify critical data dependencies and define fallback mechanisms.
Assess whether key data sources are stable and under your control or subject to third-party risks.
Monitor availability of inputs to catch outages early.
Imagine you planned to feed your model with input obtained by mining surveys and it appears these surveys contain a lot of free text fields. To prepare that data and avoid issues (bias, inaccuracies, etc) you might need extra time. Consider these types of scenarios that could impact the whole life cycle of your system.
Can we process new or updated data from external sources without delay?
In high-stakes domains like healthcare or finance, delays in processing updated external data can lead to stale predictions or risky decisions.
Risks include slow ingestion pipelines, format mismatches, or batch processing delays that prevent real-time responsiveness.
How much change are you expecting in the data you receive?
Can you make sure that you receive the updates on time?
If your answer is No or MAYBE, you might be at risk
FLIPCARD
Recommendations
Design your data pipeline to handle frequent updates efficiently.
Validate incoming data formats, track data freshness, and assess update intervals.
Consider impact of delays on downstream decisions and mitigate with caching, fallback logic, or alerts.
Not only must you trust your sources, but you also need to design a process in which data is prepared on time to be used in the model and where you can timely consider the impact it could have in the output of the model, especially when this could have a negative impact on the users and system's behaviour. This process can be designed once you know how often changes in the data can be expected and how big the changes are.
Data Legitimacy
Are all required data sources legitimate, authorized, and verified?
Data lineage can be necessary to demonstrate trust as part of your information transparency policy, but it can also be very important when it comes to assessing impact on the data flow. If sources are not verified and legitimized you could run risks such as data being wrongly labelled for instance.
Do you know where you need to get the data from? Who is responsible for the collection, maintenance and dissemination? Are the sources verified? Do you have the right agreements in place? Are you allowed to receive or collect that data? Also keep ethical considerations in mind!
If your answer is No or MAYBE, you might be at risk
FLIPCARD
Recommendations
Develop a robust understanding of your relevant data feeds, flows and structures such that if any changes occur to the model data inputs, you can assess any potential impact on model performance. In case of third party AI systems contact your vendor to ask for this information.
If you are using synthetic data you should know how it was created and the properties it has. Also keep in mind that synthetic data might not be the answer to all your privacy related problems; synthetic data does not always provide a better trade-off between privacy and utility than traditional anonymisation techniques.
Do you need to share models and combine them? The usage of Model Cards and Datasheets can help providing the source information.
Can we obtain the data needed to develop or fine-tune the AI model?
Could you face difficulties obtaining certain type of data? This could be due to different reasons such as legal, proprietary, financial, physical, technical, etc. This could put the whole project in danger.
If your answer is No or MAYBE, you might be at risk
FLIPCARD
Recommendations
In the early phases of the project (as soon as the task becomes more clear), start considering which raw data and types of datasets you might need. You might not have the definitive answer until you have tested the model, but it will already help to avoid extra delays and surprises. You might have to involve your legal and financial department. Remember that this is a team effort.
Data Traceability
Can we trace the provenance and lineage of the data used to train or fine-tune the AI model?
AI models require traceability of data sources to ensure ethical usage, reproducibility, and compliance. Without proper data lineage, it is difficult to verify the credibility and accuracy of training data.
If your answer is No or MAYBE, you might be at risk
FLIPCARD
Recommendations
Use data lineage tracking tools to monitor where data originates and how it is modified over time.
Implement metadata standards (e.g., Datasheets for Datasets) to ensure clear documentation of data sources.
Regularly audit data providers to verify their reliability and adherence to ethical guidelines.
Could our dataset have copyright or other legal restrictions?
Consider any legal, licensing, or privacy constraints that might prevent you from using certain datasets. This also applies to proprietary libraries, tools, or other resources.
If your answer is Yes or MAYBE, you might be at risk
FLIPCARD
Recommendations
Consider if you also need to claim ownership or give credits to creators.
Think about trademarks, copyrights in databases or training data, patents, license agreements that could be part of the dataset, library or module that you are using.
Legal ownership of digital data can sometimes be complex and uncertain so get the proper legal advice here.
Data Integrity
Can we detect and prevent data tampering across the AI lifecycle?
Data integrity is critical to ensuring that AI systems function as intended. Tampered data, whether during ingestion, transformation, storage, or transfer, can introduce hidden errors, biases, or malicious payloads. AI models built on compromised data may behave unpredictably, yield incorrect results, or violate compliance requirements. Integrity threats may be unintentional (e.g., pipeline errors) or deliberate (e.g., insider sabotage or supply chain attacks).
CIA traid impact: Integrity
If your answer is No or MAYBE, you might be at risk
FLIPCARD
Recommendations
Implement data integrity checks (e.g., hashes, checksums) at critical stages of the data pipeline.
Use tamper-evident storage (e.g., append-only logs, signed records).
Employ data lineage and provenance tracking systems to trace the origin and transformation history of data.
Apply anomaly detection to catch unexpected shifts or inconsistencies in inputs.
Audit access to data and enforce change tracking on data sources used for training or inference.
Does the AI system need to be explainable for users or affected persons?
Is the algorithm transparent, or is it a 'black box' that users cannot interpret?
Can users learn about how the model works?
Is the model explainable, and are you open about the data used for training, including where and how it was sourced?
If your answer is Yes or MAYBE, you might be at risk
FLIPCARD
Recommendations
Evaluate the type of models that you could use to solve the problem as specified in your task.
Consider what the impact is if certain black box models cannot be used and interpretability tools do not offer sufficient results. You might need to evaluate a possible change in strategy.
An explainable AI system refers not only to the model but also the user interfaces, data pipelines, and other components supporting the model's deployment and interpretation.
Data scientists can evaluate the impact from a technical perspective and discuss this with the rest of stakeholders. The decision keeps being a team effort.
AI systems must be designed to be accessible and inclusive, particularly for individuals who may face barriers due to age, disability, or other vulnerabilities.
Think, for instance, of elderly people, children, or people with disabilities or individuals with cognitive impairments. Does the system support assistive technologies (e.g., screen readers)? Are there text alternatives, simplified navigation, or options for non-standard input and output formats?
Accessibility also includes cognitive accessibility: does the system assume a certain level of AI literacy or digital fluency that may not be present in all users? Are users supported with clear explanations, educational materials, or onboarding tools?
Inaccessible AI can lead to exclusion, discrimination, reduced autonomy, or even harm, violating fundamental rights under the Charter of Fundamental Rights of the EU (Articles 21: Non-discrimination, 24: Rights of the child, and 26: Integration of persons with disabilities).
The AI Act (Article 4) also highlights the need for systems to be inclusive and safe by design.
If your answer is No or MAYBE, you might be at risk
FLIPCARD
Recommendations
Conduct an impact assessment focusing on accessibility and vulnerability.
Involve affected groups and advocacy organizations in the design and testing phase.
Design interfaces that comply with Web Content Accessibility Guidelines (WCAG) and ensure compatibility with assistive technologies.
Avoid manipulative patterns (e.g., dark patterns) that exploit reduced digital literacy or cognitive overload.
Document accessibility limitations in model/system cards and ensure clear communication to users and caregivers.
Ensure age-appropriate design and protections for children, including safe defaults and data minimization.
If users’ consent is required, is the necessary information provided in a clear and accessible way?
Is the consent information presented in a way that is easy for users to access and understand?
Do you need to create a dedicated place to display consent information, especially in contexts where a traditional text interface is not available (e.g., voice-based systems or robots)?
If your answer is No or MAYBE, you might be at risk
FLIPCARD
Recommendations
As part of privacy compliance you need to provide clear information about the processing and the logic of the algorithm. This information should be easily readable and accessible. During the design phase consider when and how you are going to provide this information.
Could the user perceive the message from the AI system in a different way than intended?
Does the user’s perception of the information match the intended meaning?
The way AI communicates, tone, language, and context, can lead to misinterpretation, influenced by factors like cultural background or prior experiences.
If your answer is Yes or MAYBE, you might be at risk
FLIPCARD
Recommendations
Understanding who is going to interact with the AI system can help to make the interaction more effective. Identify your different user groups.
Involve communication experts and do enough user testing to reduce the gap between the intended and the perceived meaning.
Is the AI system easy for users to learn and operate?
Does the system require a minimum level of AI literacy to be used?
Could a steep learning curve lead to misuse or harm?
How quickly are users expected to learn how to use the product?
Do you ensure that users have access to the necessary learning materials needed to be able to use the system?
Difficulties in learning how the system works could also bring the users in danger and have consequences for the reputation of the product or organisation.
If your answer is No or MAYBE, you might be at risk
FLIPCARD
Recommendations
You can provide assistance, appropriate training material and disclaimers to users on how to adequately use the system.
The words and language used in the interface, the complexity and lack of accessibility of some features could exclude people from using the application. Consider making changes in the design of the product where necessary.
Consider this also when children are possible users.
Are users clearly made aware that they are interacting with an AI system or consuming AI-generated content?
Users must be clearly informed when they are interacting with an AI system, especially in conversational interfaces, automated decision systems, or content generation tools. Failing to do so can undermine user trust, autonomy, and informed consent.
This includes both real-time interactions (e.g., chatbots) and offline consumption of AI-generated content (e.g., synthetic images, deepfakes).
Deepfakes and other AI-generated media that imitate real individuals or events carry high risks of deception, manipulation, and reputational harm if not transparently disclosed.
Lack of disclosure may also breach Article 50 of the EU AI Act and broader transparency obligations under the GDPR.
If your answer is No or MAYBE, you might be at risk
FLIPCARD
Recommendations
Inform users at the start of any interaction that they are engaging with an AI system, especially in systems simulating human communication (e.g., chatbots, virtual assistants).
For generative AI outputs (text, audio, video, images), ensure they are clearly marked, both visibly and in machine-readable format, as artificially generated or manipulated.
If your system produces deepfakes or synthetic media, implement persistent and tamper-resistant labeling or watermarks and include a notice that the content has been artificially generated or altered.
Deployers must also inform users when emotion recognition, biometric categorization, or similar AI functions are in use.
Design your UX to surface these disclosures prominently and accessibly, particularly in sensitive contexts such as news, education, or political speech.
Interesting resources/references
Article 50 AI Act
System Transparency for Effective Use
Are users informed about the AI system's reliability, limitations, and risks in a way that enables safe and effective use?
Users need to understand what the AI system can and cannot do, including its intended use, reliability, limitations, and potential risks. Without clear communication, users may place unwarranted trust in the system, misuse it, or be harmed by misleading outputs. This undermines transparency, fairness, safety, and user autonomy. For example, failing to disclose error rates, decision logic, or appropriate use contexts can lead to over-reliance or unsafe behavior, especially in sensitive domains.
If your answer is No or MAYBE, you might be at risk
FLIPCARD
Recommendations
Clearly communicate the system's intended use, benefits, limitations, and potential risks.
Provide timely, accessible information on accuracy levels, error rates, interpretability, and system updates.
Ensure users understand when and how to rely on the system, and when human judgment is needed.
Use interpretability tools appropriate to the impact of the system, especially if it is a black-box model.
Follow accessibility best practices to ensure all users, including those with disabilities, can understand the system.
Incorporate feedback loops such as surveys to verify that users actually understand how the system works and what they can expect.
Consider this part of compliance with the GDPR transparency principle, and good practice for system safety and usability.
Do you need to use unique identifiers in your training or fine-tuning dataset? If personal data is not necessary for the model you would not really have a legal justification for using it.
Training datasets for LLMs may inadvertently include personal data, leading to potential privacy breaches. Even if direct identifiers are removed, indirect identifiers or quasi-identifiers can still enable re-identification. This poses risks under data protection regulations like the GDPR, especially if the data subjects have not provided explicit consent for their data to be used in this manner.
If your answer is Yes or MAYBE, you might be at risk
FLIPCARD
Recommendations
Unique identifiers might be included in the training set when you want to be able to link the results to individuals. Consider using pseudo-identifiers or other robust pseudonymization techniques that can help you protect personal data.
Document the measures you are taking to protect the data. Consider if your measures are necessary and proportional.
Could the AI system infer and reveal information that a person has not explicitly shared?
How can you make sure the product doesn’t inadvertently disclose sensitive or private information during use (e.g., indirectly inferring location, behaviour or connection between digital and physical identity of users)?
Could movements or actions be revealed through data aggregation?
If your answer is Yes or MAYBE, you might be at risk
FLIPCARD
Recommendations
Be careful when making data public that you think is anonymised. Location data and routes can sometimes be de-anonymised (e.g. users of a running app disclosing location by showing heatmap).
It is also important to offer privacy by default: offer the privacy settings by default at the maximum protection level. Let the users change the settings after having offered them clear information about the consequences of reducing the privacy levels.
Local Restrictions
Could geolocation restrictions or regional regulations impact the implementation of our AI system in other countries?
AI systems often process sensitive data, including personal or location-based information, which may be subject to regional data sovereignty laws and ethical restrictions. Additionally, certain countries may restrict the deployment of AI technologies based on local regulatory frameworks, ethical concerns, or national security considerations. This could limit the usage of your product in those regions.
If your answer is Yes or MAYBE, you might be at risk
FLIPCARD
Recommendations
Stay informed about the evolving regulatory landscape for AI, including data sovereignty, privacy laws, and ethical standards in different countries. Engage legal and compliance experts to assess restrictions in your target markets.
Consider designing your AI system with adaptability for regional requirements, such as geofencing, localized processing, or compliance with specific regulations (e.g., GDPR, AI Act, CCPA).
Monitor new AI-related regulations and international agreements to proactively address potential restrictions or adapt your system to comply with local laws.
Data Minimization
Can we minimize the amount of personal data used while preserving model performance?
The principle of data minimization, as outlined in the General Data Protection Regulation (GDPR) and reflected in many global privacy standards, requires that only data necessary for achieving the system's purpose is collected and processed. However, reducing data too much can sometimes negatively impact the accuracy and performance of AI models, leading to critical or damaging consequences. Balancing regulatory compliance with operational effectiveness is essential to avoid undermining the model's reliability while adhering to privacy principles.
If your answer is No or MAYBE, you might be at risk
FLIPCARD
Recommendations
Achieve data minimization by starting with a smaller dataset and iteratively adding data only as needed, based on observed performance improvements, to justify why additional data is necessary.
Use high-quality data to reduce the need for large datasets while ensuring sufficient diversity and representativeness for your model.
Apply advanced privacy-preserving techniques such as pseudonymization, perturbation, differential privacy, federated learning, or synthetic data generation to comply with privacy regulations while using larger datasets.
Collaborate with experts to select the minimum set of features needed, ensuring relevance to the objective and avoiding issues like the Curse of Dimensionality, which can degrade model performance when unnecessary features are included.
Data Minimization for GDPR Compliance in Machine Learning Models: Methods like the one proposed in this paper can inspire you to find a way to mitigate the accuracy risk. They show how to reduce the amount of personal data needed to perform predictions, by removing or generalizing some of the input features.
Are we processing special categories of personal data or sensitive data?
According to art. 9 GDPR you might not be allowed to process, under certain circumstances, personal data revealing racial or ethnic origin, political opinions, religious or philosophical beliefs, trade union membership, genetic data, biometric data, health data or data concerning a person’s sex life or sexual orientation.
You might be processing sensitive data if the model includes features that are correlated with these protected characteristics (these are called proxies) but also if you are processing other type of data that, if disclosed, could cause harm (e.g., financial data)
If your answer is Yes or MAYBE, you might be at risk
FLIPCARD
Recommendations
If you need to use special categories of data as defined in the GDPR art. 9, then you need to check if you have the right lawful basis to do this.
Applying techniques like anonymisation might still not justify the fact that you first need to process the original data. Check with your privacy/legal experts.
Prevent proxies that could infer sensitive data (especially from vulnerable populations).
Check whether historical data or practices may introduce bias.
Identify and remove features that are correlated to sensitive characteristics.
Use available methods to test for fairness with respect to different affected groups.
Could the AI system make decisions with legal or similarly significant effects without human intervention?
AI systems that make decisions without human oversight may fall under GDPR Article 22, which restricts significant automated decisions unless specific safeguards are in place. These decisions can affect individuals’ rights, legal status, or access to services.
Additionally, Article 86 of the AI Act requires transparency and the provision of clear explanations for significant decisions made by high-risk AI systems.
If your answer is Yes or MAYBE, you might be at risk
FLIPCARD
Recommendations
Consult privacy and legal experts to determine whether your system qualifies under Article 22 of the GDPR.
Implement mechanisms for human intervention, contestability, and explanation. Article 22(3) of the GDPR provides individuals with the right to obtain human intervention in automated decisions and the right to contest such decisions.
Align with the EU AI Act's oversight and transparency requirements.
Ensure that impacted users are informed of their rights and can seek human review.
Maintain documentation of decision logic, oversight processes, and risk mitigation strategies.
Do we have a valid legal basis for processing personal data?
Do you know which GDPR legal ground you can apply?
(a) Consent: the individual has given clear consent for you to process their personal data for a specific purpose.
(b) Contract: the processing is necessary for a contract you have with the individual, or because they have asked you to take specific steps before entering into a contract.
(c) Legal obligation: the processing is necessary for you to comply with the law (not including contractual obligations).
(d) Vital interests: the processing is necessary to protect someone’s life.
(e) Public task: the processing is necessary for you to perform a task in the public interest or for your official functions, and the task or function has a clear basis in law.
(f) Legitimate interests: the processing is necessary for your legitimate interests or the legitimate interests of a third party, except where such interests are overridden by the interests or fundamental rights and freedoms of the individual which require protection of personal data, in particular where the individual is a child. (This cannot apply if you are a public authority processing data to perform your official tasks.)
If your answer is No or MAYBE, you might be at risk
FLIPCARD
Recommendations
In the case of the GDPR you need to be able to apply one of the six available legal grounds for processing the data (art. 6).
Check with your privacy expert, not being able to apply one of the legal grounds could bring the project in danger.
Take into account that other laws besides the GDPR may also apply.
Could we be using personal data for purposes different from those for which it was originally collected?
The principle of purpose limitation, as defined in the General Data Protection Regulation (GDPR) and echoed in many global privacy frameworks, requires that personal data is collected for specified, explicit, and legitimate purposes and not further processed in a way incompatible with those purposes. Data repurposing is a significant challenge when applying this principle. If datasets were originally collected for a different purpose, their reuse without proper consent or legal justification may violate privacy regulations and ethical standards.
If your answer is Yes or MAYBE, you might be at risk
FLIPCARD
Recommendations
Consult with your privacy officer or legal team to verify the original purpose of the data collection and evaluate any constraints or legal requirements.
If data repurposing is necessary, consider obtaining additional consent, performing a legitimate interest assessment, or applying anonymization techniques to ensure compliance.
Additionally, document all decisions and justifications for data reuse to demonstrate accountability under privacy regulations.
Data Subject Rights
Are we able to comply with all the applicable GDPR data subjects’ rights?
Can you implement the right to withdraw consent, the right to object to the processing and the right to be forgotten into the development of the AI system?
Can you provide individuals with access and a way to rectify their data?
If your answer is No or MAYBE, you might be at risk
FLIPCARD
Recommendations
Complying with these provisions from the GDPR (art. 15-21) could have an impact on the design of your product. What if users withdraw their consent? Do you need to delete their data used to train the model? What if users can no longer be identified in the dataset? And what information should the users have access to?
Consider all these possible scenarios and involve your privacy experts early in the design phase.
Privacy Impact Assessment
Could we be deploying the AI system without conducting a required Data Protection Impact Assessment (DPIA)?
The use of AI is more likely to trigger the requirement for a DPIA, based on criteria in Article 35 GDPR. The GDPR and the EDPB’s Guidelines on DPIAs identify both “new technologies” and the type of automated decision-making that produce legal effects or similarly significantly affect persons as likely to result in a “high risk to the rights and freedoms of natural persons”.
If your answer is Yes or MAYBE, you might be at risk
FLIPCARD
Recommendations
This threat modeling library can help you to assess possible risks.
Remember that a DPIA is not a piece of paper that needs to be done once the product is in production. The DPIA starts in the design phase by finding and assessing risks, documenting them and taking the necessary actions to create a responsible product from day one until it is finalized.
Consider the time and resources that you might need for the execution of a DPIA, as it could have some impact on your project deadlines.
Third-party Data Processing
Are we using third-party providers while processing data from children or other vulnerable individuals?
If your system processes data from children or other vulnerable groups, any third-party providers you rely on (such as libraries, SDKs, or other tools) may also have access to this data. In such cases, you must ensure they comply with relevant privacy regulations like GDPR, COPPA, or similar frameworks. Even if your own system adheres to strong data protection measures, vulnerabilities or non-compliance on the part of third-party providers could expose sensitive data or create ethical risks.
If your answer is Yes or MAYBE, you might be at risk
FLIPCARD
Recommendations
Audit all third-party applications, libraries, and tools you use to determine what data they collect and ensure they comply with applicable regulations.
Confirm that proper agreements (e.g., Data Processing Agreements) are in place with all third-party providers to specify how data is handled.
Where possible, configure third-party tools to limit or avoid sharing sensitive data. Implement pseudonymization or anonymization techniques to protect data before sharing.
Evaluate the necessity of each third-party provider. If risks are identified, consider replacing or discontinuing use of certain providers, weighing the operational impact on your organization.
Metadata
Are we using metadata that could reveal personal data or behavior patterns?
Metadata provides descriptive attributes of other data, such as date, time, author, file size, or geolocation.
Although metadata may seem innocuous, it is often considered personal data under privacy regulations (e.g., GDPR) and can contain sensitive information. Misusing or failing to protect metadata can lead to privacy violations and unintended risks, especially if it reveals identifiable information.
If your answer is Yes or MAYBE, you might be at risk
FLIPCARD
Recommendations
Ensure that your use of metadata complies with applicable privacy regulations by verifying whether the data can be lawfully processed for your intended purpose.
Audit and verify metadata sources to confirm their accuracy and legitimacy.
Implement anonymization or pseudonymization techniques to minimize privacy risks while using metadata.
Limit the collection of metadata to only what is strictly necessary for the model, adhering to the principle of data minimization.
Privacy Rights
Could we compromise users’ rights to privacy and to a private and family life?
The AI system may intrude on users' right to privacy by exposing sensitive aspects of their private lives, such as personal behaviors, preferences, or relationships, without their explicit consent or awareness. This can occur through excessive surveillance, unintended inferences, profiling, or sharing personal data without proper safeguards. Such compromises may undermine users' autonomy, dignity, and trust in the system, leading to legal, ethical, and reputational consequences for providers.
If your answer is Yes or MAYBE, you might be at risk
FLIPCARD
Recommendations
Ensure that the AI system respects the contextual integrity of users' private lives by limiting inferences and decisions to what is strictly necessary for its intended purpose.
Minimize the risk of profiling that could reveal sensitive personal attributes or behaviors unless explicitly justified by the intended use and supported by users’ consent or legal ground.
Design the AI system to avoid unnecessary observation or analysis of users’ private spaces, behaviors, or communications unless explicitly required by the use case.
Provide clear and accessible information to users about the extent and nature of the AI system's interaction with their private lives, ensuring that they are fully informed about its capabilities.
Empower users to set boundaries for their privacy by allowing them to control the scope of data collection and interaction with the AI system (Privacy by default).
Include ethical reviews and stakeholder consultations to assess the potential implications of the system on users’ privacy in diverse cultural and social contexts.
Implement safeguards to prevent the system from drawing unintended, intrusive, or harmful conclusions about individuals’ private lives.
Ensure robust security measures to prevent unauthorized access, surveillance, or other misuse of the system that could violate users’ privacy rights.
Provide mechanisms for users to report and address concerns if they feel their privacy has been violated, including remedies for potential harm caused.
Interesting resources/references
Right to privacy (Universal Declaration of Human Rights), Article 7 Respect for Private and Family Life (Charter of fundamental rights of the European Union)
Transparent Information
Are we providing sufficient transparency about how the AI model collects, processes, and uses personal data?
Users and stakeholders may not fully understand how data is collected, processed, and utilized, leading to concerns about privacy, accountability, and trust. A lack of transparency can make it difficult to verify whether personal data is being used lawfully or ethically. AI decision-making may be opaque, increasing risks of bias, discrimination, or unfair outcomes.
If your answer is No or MAYBE, you might be at risk
FLIPCARD
Recommendations
Implement explainability tools that provide insights into AI decision-making.
Use clear and accessible documentation detailing data collection, storage, processing, and sharing.
Follow transparency principles from the EU AI Act and GDPR regarding automated decision-making.
Utilize model cards, data sheets, and algorithmic auditing to enhance transparency.
Storing of User Data
Are we logging or storing user input data in ways that may violate privacy?
AI systems, particularly Large Language Models (LLMs), may log user inputs and outputs for debugging or model fine-tuning, potentially storing sensitive data without explicit user consent. Logged data could be included in training datasets, making it possible for adversaries to conduct data poisoning attacks, influencing model behavior. Even metadata from logs may reveal sensitive details about users.
If your answer is Yes or MAYBE, you might be at risk
FLIPCARD
Recommendations
Implement strict access controls and data minimization techniques to prevent excessive logging.
Provide opt-in or opt-out options for data collection and obtain explicit consent where needed.
Regularly audit and delete logs containing personal or sensitive data.
Use differential privacy, encryption, or synthetic data to minimize risks while analyzing logs.
Detect and mitigate adversarial attacks aimed at poisoning training data.
Could the AI system produce inaccurate or misleading outputs that result in privacy violations or harm?
AI systems may generate, infer, or reproduce incorrect personal data, leading to violations of the GDPR’s accuracy principle (Article 5(1)(d)) and potential harm to data subjects.
Outputs may inadvertently reveal sensitive data or personal details, leading to privacy breaches.
In traditional AI, this includes misclassification, profiling errors, or incorrect risk scoring that affect decisions about individuals (e.g., in hiring, finance, law enforcement).
In generative AI, this includes hallucinated personal facts or fabricated content that falsely attributes actions, identities, or characteristics to real people. When multiple AI agents interact, hallucinations and errors can amplify, increasing the likelihood of spreading misinformation.
These inaccuracies can damage reputations, mislead users, or be stored and processed in downstream systems, compounding the data protection risk.
If your answer is Yes or MAYBE, you might be at risk
FLIPCARD
Recommendations
Conduct data protection impact assessments (DPIAs) to evaluate how inaccurate outputs could affect individuals' rights and freedoms.
Provide mechanisms for individuals to access, rectify, or contest inferences or decisions made by AI systems.
Maintain logs and audit trails to trace how inaccurate personal data was generated or propagated.
Train models with high-quality, up-to-date, and verified datasets to minimize the risk of misinformation and outdated personal data
For generative AI:
Implement fact-checking and validation mechanisms before AI-generated responses are shown to users.
Implement named-entity detection and filtering to prevent false personal information from being output
Use retrieval-augmented generation (RAG) and human-in-the-loop (HITL) approaches to improve accuracy.
Red-team AI models by stress-testing them for misinformation and privacy risks.
Allow users to report inaccurate or harmful content, enabling iterative model improvements.
Restrict AI-generated outputs on sensitive topics unless rigorous verification is in place.
For traditional AI (e.g., classification, regression, or rule-based systems):
Validate models on diverse, real-world datasets to test for generalizability and edge-case failures.
Implement post-deployment performance monitoring and regular retraining to reduce drift and degradation over time.
Conduct error analysis on false positives and false negatives to refine model logic and thresholds.
Include uncertainty estimation and confidence scoring to guide decision-making, especially in high-risk use cases.
In safety-critical applications, ensure fallback mechanisms or manual review paths are available when confidence is low.
Can we comply with the storage limitation principle and international data retention regulations?
The principle of storage limitation, as stated in Article 5(e) of the GDPR, requires personal data to be stored only as long as necessary for the intended purpose. Similarly, many global privacy regulations, such as CCPA (California), LGPD (Brazil), and PDPB (India), impose strict rules on data retention and deletion. Do you have a clear understanding of how long you need to keep the data (training data, output data, etc.) and whether you comply with internal, local, national, or international retention requirements?
If your answer is No or MAYBE, you might be at risk
FLIPCARD
Recommendations
Personal data must not be stored longer than necessary for its intended purpose. Compliance requires a clear understanding of the data flow throughout the model’s lifecycle.
Analyze all data types, including raw input data, training and testing sets, processed outputs (linked or merged data), and associated metrics. Understand where this data will be stored and for how long.
Define clear retention and deletion schedules, ensuring responsible individuals are assigned for managing data retention and disposal.
If data must be retained for auditing or quality purposes, anonymize it where possible to minimize privacy risks.
Stay informed about and comply with retention rules not only under GDPR but also under international frameworks such as CCPA (California Consumer Privacy Act), LGPD (Brazilian General Data Protection Law), and others. Retention and deletion policies should meet these diverse requirements.
Be aware that deleting data from a trained model is inherently challenging, as input data influences the model's internal representation during training. Consider legal implications for the model itself, as encoded thresholds and weights may also be subject to retention laws. Source: BerryvilleiML
Security Testing
Could we be deploying the AI system without testing for adversarial robustness and systemic vulnerabilities?
AI systems can be targeted in unique ways, such as adversarial inputs, poisoning attacks, or reverse-engineering of model outputs. These threats could compromise the system's confidentiality, integrity, and availability, leading to reputational damage or harm to users. Testing for these issues may require specialized expertise, tools, and time, which could affect project timelines.
CIA traid impact: ConfidentialityIntegrityAvailability
If your answer is Yes or MAYBE, you might be at risk
FLIPCARD
Recommendations
Plan for AI-specific penetration testing or red-teaming exercises, focusing on adversarial robustness, data governance, and model-specific vulnerabilities. Allocate time in the project for external audits, agreement on scope, and retesting if vulnerabilities are found.
Are our AI inference APIs and function-calling interfaces securely implemented?
AI systems increasingly rely on APIs for inference (e.g., LLM endpoints), orchestration (e.g., function calls via tools), or dynamic prompt injection (e.g., Model Context Protocol). Poorly secured APIs expose attack surfaces specific to LLMs and other AI models.
Threats include:
Prompt injection via API inputs or user tool outputs (e.g., using MCP-style interfaces).
Malicious function calls that exploit insecure tool execution pipelines.
Abuse of structured output endpoints (e.g., JSON-formatted APIs) to extract or manipulate model behavior.
Reverse-engineering model behavior via inference chaining or output probing.
Attacks on shared foundational model APIs can impact multiple downstream applications through shared vulnerabilities, hallucination exploits, or jailbreak discovery.
CIA traid impact: ConfidentialityIntegrityAvailability
If your answer is No or MAYBE, you might be at risk
FLIPCARD
Recommendations
Implement security best practices:
Use strong authentication mechanisms such as API keys or OAuth.
Enforce role-based access controls (RBAC) to restrict functionality.
Encrypt data at rest and in transit (TLS).
Validate and sanitize all inputs; apply strict content-type controls.
Use allowlists and structured schemas (e.g., OpenAPI, JSON Schema) to constrain behavior.
Avoid exposing secrets in API calls or payloads.
Regularly test APIs for vulnerabilities including injection attacks, improper state management, and rate limit bypasses.
Deploy anomaly detection to flag adversarial or abnormal usage patterns.
Limit API output granularity to prevent reverse engineering; obfuscate or truncate confidence scores.
Monitor and log all API interactions to detect and investigate abuse.
Rate-limit and throttle access to prevent enumeration or prompt probing.
For LLMs with plugin, function-calling, or Model Context Protocol (MCP) interfaces:
Monitor for prompt injection and abuse chains across tools.
Apply zero-trust design principles to inference and orchestration layers.
Red-team APIs and function interfaces regularly.
Collaborate with foundational model providers to validate the security of shared inference APIs and plugin-style architectures.
Are training data, model output, and other sensitive AI assets securely stored?
Is your data stored and managed in a secure way? Think about training data, tables, models, outputs, etc. Do only authorized individuals have access to your data sources?
Source: BerryVilleiML
CIA traid impact: ConfidentialityIntegrityAvailability
If your answer is No or MAYBE, you might be at risk
FLIPCARD
Recommendations
Implement access control rules.
Verify the security of the authentication mechanism (and the system as a whole).
Consider the risk when utilizing public/external data sources.
If the AI system uses randomness, is the source of randomness properly protected?
Randomness plays an important role in stochastic systems. “Random” generation of dataset partitions may be at risk if the source of randomness is easy to control by an attacker interested in data poisoning.
Source: BerryVilleiML
CIA traid impact: Integrity
If your answer is No or MAYBE, you might be at risk
FLIPCARD
Recommendations
Use of cryptographic randomness sources is encouraged. When it comes to machine learning (ML), setting weights and thresholds “randomly” must be done with care. Many pseudo-random number generators (PRNG) are not suitable for use. Improper PRNG loops can degrade system behavior and lead to unpredictable learning. Cryptographic randomness directly intersects with ML when it comes to differential privacy. Using the wrong sort of random number generator can lead to subtle security problems.
Source: BerryVilleiML
Is the AI model suited for processing confidential information?
There are certain kinds of machine learning (ML) models which actually contain parts of the training data in its raw form within them by design. For example, ‘support vector machines’ (SVMs) and ‘k-nearest neighbours’ (KNN) models contain some of the training data in the model itself.
Algorithmic leakage is an issue that should be considered carefully.
Source: BerryVilleiML
CIA traid impact: Confidentiality
If your answer is No or MAYBE, you might be at risk
FLIPCARD
Recommendations
When selecting the algorithm, conduct a thorough analysis to evaluate the risk of algorithmic leakage. For models known to retain training data (e.g., k-nearest neighbors, support vector machines), assess whether sensitive or identifiable information could be exposed through predictions or reverse engineering.
Perform privacy risk assessments and adversarial testing to detect memorization or data leakage.
Use privacy-preserving techniques where appropriate (e.g., differential privacy, data minimization, feature abstraction).
Avoid using algorithms prone to leakage when working with sensitive data, or take extra steps to anonymize and sanitize training inputs.
Include leakage testing in your model evaluation pipeline, especially for high-risk or regulated domains.
Have we implemented safeguards to detect and prevent insider threats to our AI systems?
AI designers and developers may deliberately expose data and models for a variety of reasons, e.g. revenge or extortion. Integrity, data confidentiality and trustworthiness are the main impacted security properties. Source: ENISA
CIA traid impact: ConfidentialityIntegrityAvailability
If your answer is No or MAYBE, you might be at risk
FLIPCARD
Recommendations
Implement onboarding and offboarding procedures to ensure the trustworthiness of internal and external personnel.
Enforce separation of duties and least privilege principle.
Enforce the usage of managed devices with appropriate policies and protective software.
Implement awareness training.
Implement strict access control and audit trail mechanisms.
Have we protected our AI system against model sabotage?
Model sabotage involves deliberate manipulation or damage to AI systems at any stage, from development to deployment. This can include embedding backdoors, altering model behavior, or exploiting vulnerabilities in training data, third-party tools, or infrastructure.
For AI providers: Risks include compromised training datasets, malicious code in open-source libraries, or backdoors introduced during development.
For AI deployers: Threats arise from integrating tampered models, using insecure APIs, or applying updates that introduce vulnerabilities.
CIA traid impact: ConfidentialityIntegrityAvailability
If your answer is No or MAYBE, you might be at risk
FLIPCARD
Recommendations
Implement strong security measures, including regular audits and penetration testing, to ensure the integrity of models and the platforms hosting them.
Assess and monitor the security profile of third-party libraries, tooling, and providers to ensure they are not compromised.
Develop and maintain a robust disaster recovery plan with explicit mitigation strategies for model sabotage scenarios.
Use model inspection tools to detect backdoors and ensure that the model’s behavior aligns with its intended function.
Incorporate supply chain security principles by verifying the authenticity and integrity of the components used in model development and deployment.
Maintain strict version control to detect and prevent unauthorized changes to libraries or model artifacts.
Implement anomaly detection systems to identify unusual usage patterns that may indicate attempted sabotage or exploitation.
Evasion attacks involve modifying the input data to evade detection or classification by the model. These attacks can be used to bypass security systems, such as intrusion detection systems or spam filters. Example: Specific malware is crafted to avoid being flagged by a machine-learning-based antivirus.
CIA traid impact: Integrity
If your answer is No or MAYBE, you might be at risk
FLIPCARD
Recommendations
Develop anomaly detection systems to monitor deviations in input distributions and flag suspicious patterns.
Integrate robust logging mechanisms to analyze and mitigate the impact of detected attacks.
Train models with diverse and adversarial data, including known evasion techniques.
Implement ensemble modeling to reduce susceptibility to evasion attacks.
Ensure that thresholds and rules are periodically reviewed to adapt to evolving evasion techniques.
In a poisoning attack, the goal of the attacker is to contaminate the training data or the model generated in the training phase, so that predictions on new data will be modified in the testing phase. This attack could also be caused by insiders. Example: in a medical dataset where the goal is to predict the dosage of a medicine using demographic information, researchers introduced malicious samples at 8% poisoning rate, which changed the dosage by 75.06% for half of the patients.
Other scenarios:
Data tampering: Actors like AI/ML designers and engineers can deliberately or unintentionally manipulate and expose data. Data can also be manipulated during the storage procedure and by means of some processes like feature selection. Besides interfering with model inference, this type of threat can also bring severe discriminatory issues by introducing bias.
Source: ENISA
An attacker who knows how a raw data filtration scheme is set up may be able to leverage that knowledge into malicious input later in system deployment.
Source:BerryVilleiML
Adversaries may fine-tune hyper-parameters and thus influence the AI system’s behavior. Hyper-parameters can be a vector for accidental overfitting. In addition, hard to detect changes to hyper-parameters would make an ideal insider attack.
Source: ENISA
CIA traid impact: Integrity
If your answer is No or MAYBE, you might be at risk
FLIPCARD
Recommendations
Define anomaly sensors to look at data distribution on a day to day basis and alert on variations.
Measure training data variation on daily basis. Telemetry for skew/drift.
Input validation, both sanitization and integrity checking.
In a model inversion attack, if attackers already have access to some personal data belonging to specific individuals included in the training data, they can infer further personal information about those same individuals by observing the inputs and outputs of the ML model.
In model inversion the private features used in machine learning models can be recovered. This includes reconstructing private training data that the attacker should not have access to. Example: an attacker recover private features used by the model through careful queries.
CIA traid impact: Confidentiality
If your answer is No or MAYBE, you might be at risk
FLIPCARD
Recommendations
Interfaces to models trained with sensitive data need strong access control.
Implement rate-limiting on the queries allowed by the model.
Implement gates between users/callers and the actual model by performing input validation on all proposed queries, rejecting anything not meeting the model’s definition of input correctness and returning only the minimum amount of information needed to be useful.
Are we protected from membership inference attacks?
In a membership inference attack (MIA), the attacker can determine whether a given data record was part of the model’s training dataset or not. Example: researchers were able to predict a patient’s main procedure (e.g., surgery the patient went through) based on the attributes (e.g., age, gender, hospital).
CIA traid impact: Confidentiality
If your answer is No or MAYBE, you might be at risk
FLIPCARD
Recommendations
Differential Privacy has been shown to be an effective mitigation in some studies.
The usage of neuron dropout and model stacking can be effective mitigations to an extent. Using neuron dropout not only increases resilience of a neural net to this attack, but also increases model performance.
In model stealing, the attackers can recreate the underlying model by legitimately querying the model. The functionality of the new model is the same as that of the underlying model. Example: in the BigML case, researchers were able to recover the model used to predict if someone should have a good/bad credit risk using 1,150 queries and within 10 minutes.
CIA traid impact: Confidentiality
If your answer is No or MAYBE, you might be at risk
FLIPCARD
Recommendations
Minimize or obfuscate the details returned in prediction APIs while still maintaining their usefulness to 'honest' applications.
Define a well-formed query for your model inputs and only return results in response to completed, well-formed inputs matching that format.
Are we protected from reprogramming deep neural nets attacks?
Specially crafted queries from an adversary can reprogram machine learning systems to a task that deviates from the creator’s original intent. Example: ImageNet, a system used to classify one of several categories of images was repurposed to count squares.
CIA traid impact: Integrity
If your answer is No or MAYBE, you might be at risk
FLIPCARD
Recommendations
Configure a strong client-server mutual authentication and access control to model interfaces.
Takedown of the offending accounts.
Identify and enforce a service-level agreement for your APIs. Determine the acceptable time-to-fix for an issue once reported and ensure the issue no longer reoccurs after the SLA expires.
Adversarial examples are a type of evasion attack where malicious inputs are deliberately crafted to mislead AI models. These inputs are minimally modified, often imperceptible to humans, but can cause the model to produce incorrect or harmful predictions. Examples include researchers demonstrating that carefully designed patterns on accessories, like sunglasses, could deceive facial recognition systems into misidentifying individuals. Such examples are particularly problematic in critical domains like healthcare, finance, and security, where incorrect predictions could lead to severe consequences.
CIA traid impact: Integrity
If your answer is No or MAYBE, you might be at risk
FLIPCARD
Recommendations
Include adversarial examples in the training data to make models more robust against similar attacks.
Apply techniques such as input normalization, noise addition, or image resizing to reduce the impact of adversarial perturbations.
Design models with built-in robustness features to detect and counteract adversarial modifications.
Use multiple models and aggregate their predictions to make it harder for adversarial examples to deceive all models simultaneously.
Develop and apply techniques that mathematically guarantee the model’s resistance to certain adversarial manipulations.
Regularly test and monitor the system for new adversarial techniques to stay ahead of potential attacks.
Could third-party AI/ML providers compromise our training data or insert backdoors?
Malicious ML providers could query the model used by a customer and recover the customer’s training data. The training process is either fully or partially outsourced to a malicious third party who wants to provide the user with a trained model that contains a backdoor. Example: researchers showed how a malicious provider presented a backdoored algorithm, wherein the private training data was recovered. They were able to reconstruct faces and texts, given the model alone.
CIA traid impact: ConfidentialityIntegrity
If your answer is Yes or MAYBE, you might be at risk
FLIPCARD
Recommendations
Research papers demonstrating the viability of this attack indicate Homomorphic Encryption could be an effective mitigation.
Train all sensitive models in-house.
Catalog training data or ensure it comes from a trusted third party with strong security practices.
Threat model the interaction between the MLaaS provider and your own systems.
Could the AI system be vulnerable to jailbreak techniques, allowing attackers to bypass safety restrictions?
Attackers can exploit jailbreak techniques to bypass an AI system’s built-in safety constraints, enabling it to generate restricted or harmful content.
Instruction Manipulation: Attackers can craft prompts that trick AI models into breaking content restrictions by rephrasing or disguising requests.
Contextual Exploitation: Some jailbreak techniques work by introducing misleading context that influences the AI’s behavior.
Adversarial Fine-Tuning: Attackers can modify AI models or create fine-tuned versions that remove ethical constraints.
CIA traid impact: ConfidentialityIntegrity
If your answer is Yes or MAYBE, you might be at risk
FLIPCARD
Recommendations
Use reinforcement learning with human feedback (RLHF) to harden AI models against jailbreak exploits.
Deploy dynamic prompt filtering to detect and block malicious jailbreak attempts in real-time.
Implement multi-layer safety protocols, ensuring that AI models reject unsafe requests consistently.
Regularly update safety mechanisms to adapt to emerging jailbreak techniques.
Conduct red team assessments to test AI resilience against adversarial jailbreak tactics.
Could the AI system be vulnerable to prompt injection attacks, leading to unauthorized access or manipulation?
AI models, particularly large language models (LLMs), are susceptible to prompt injection attacks, where adversaries craft inputs designed to override model constraints, extract sensitive data, or manipulate system behavior.
Meta Prompt Extraction: Attackers can manipulate prompts to reveal system instructions, policies, or proprietary data.
Indirect Injection Attacks: If an AI model ingests untrusted external content, such as the contents or names of uploaded files, text from emails, chat inputs, or web pages, attackers can embed hidden prompts or malicious instructions within these elements. These indirect inputs can exploit the model's processing logic to alter its behavior, produce misleading responses, or trigger unauthorized actions, even without direct access to the model's interface.
System Command Override: Specially crafted prompts could trick AI models into executing unintended actions or disclosing confidential information.
CIA traid impact: ConfidentialityIntegrity
If your answer is Yes or MAYBE, you might be at risk
FLIPCARD
Recommendations
Use input validation and sanitization to detect and neutralize malicious prompts.
Implement adversarial training to harden the AI against prompt injection attacks.
Limit the AI’s ability to access sensitive system instructions or proprietary data through context isolation.
Avoid executing model-generated outputs directly without human or automated validation. Treat model output as untrusted data, don't execute it as code or commands.
Monitor AI interactions in real-time to detect anomalous behaviors and injection attempts.
Regularly test AI models using red teaming to identify and patch vulnerabilities in prompt handling.
Is the AI training environment secured against unauthorized access and manipulation?
AI training environments often handle sensitive data and require extensive computational resources. If left unprotected, they become a target for adversaries who may attempt to steal data, modify training sets, or inject adversarial inputs.
Unauthorized Access to Training Data: Malicious actors could exfiltrate sensitive training datasets, leading to data leaks or compliance violations.
Model Poisoning & Integrity Attacks: Attackers may inject biased or adversarial data into the training process, leading to degraded or manipulated AI outputs.
Infrastructure Vulnerabilities: Misconfigured cloud environments or weak authentication mechanisms could expose training pipelines to external threats.
CIA traid impact: ConfidentialityIntegrityAvailability
If your answer is No or MAYBE, you might be at risk
FLIPCARD
Recommendations
Implement strict access controls and role-based permission for training environments.
Use end-to-end encryption for training data to prevent unauthorized interception.
Deploy secure multi-party computation (SMPC) and homomorphic encryption to protect sensitive datasets.
Regularly audit and monitor training infrastructure for security vulnerabilities.
Adopt sandboxed environments to isolate training processes and prevent malicious tampering.
Is the deployed AI system protected from unauthorized access and misuse?
Unauthorized access to AI systems can result in data breaches, model theft, and exploitation of sensitive functionalities. Without proper access control, attackers can extract model parameters, manipulate system behavior, or leak confidential data.
Credential & API Key Exposure: Weak authentication mechanisms can lead to unauthorized access, allowing attackers to exploit API endpoints or modify AI responses.
Model Extraction Attacks: Attackers can systematically query an AI system to recreate and steal proprietary models, leading to intellectual property theft.
Privilege Escalation Risks: Poorly managed user roles and permissions may allow attackers to escalate access, gaining control over critical AI operations.
CIA traid impact: ConfidentialityIntegrityAvailability
If your answer is No or MAYBE, you might be at risk
FLIPCARD
Recommendations
Enforce multi-factor authentication (MFA) and strong password policies for AI system access.
Restrict API access using role-based access control (RBAC) and least privilege principles.
Monitor AI usage logs for anomalous access patterns and potential security breaches.
Apply rate limiting and query monitoring to detect and mitigate model extraction attacks.
Use secure enclaves and differential privacy to protect sensitive AI models and training data.
Could third-party tools, plugins, or dependencies introduce vulnerabilities in our AI system?
Modern AI systems increasingly rely on external tools and plugin interfaces (e.g., Model Context Protocol, LangChain, OpenAI plugins) to expand their capabilities. These interfaces pose unique security risks if not tightly controlled.
Runtime Abuse: If tool or plugin inputs are not strictly validated, LLMs may:
Trigger unauthorized tool executions.
Bypass guardrails using structured payloads embedded in plugin responses.
Chain outputs across tools in unsafe ways (e.g., generating code that another tool executes).
Supply Chain Risks: Third-party plugins and dependencies may contain vulnerabilities or backdoors. Attackers can:
Compromise plugin registries or repositories.
Hijack dependencies to inject malicious code.
Tamper with pre-trained models or updates during distribution.
These risks are magnified in open ecosystems where tools are crowd-sourced or rapidly integrated without full vetting.
CIA traid impact: ConfidentialityIntegrityAvailability
If your answer is Yes or MAYBE, you might be at risk
FLIPCARD
Recommendations
Use strict schemas (e.g., OpenAPI, JSON Schema) and validate all tool/plugin inputs and outputs.
Treat plugin invocations as untrusted: isolate execution, rate-limit usage, and monitor behavior.
Maintain allowlists of vetted plugins and restrict file access, external requests, or execution rights.
Verify third-party components using cryptographic checksums and signatures.
Conduct regular security audits of plugins, model dependencies, and tool chains.
Adopt a zero-trust security model around plugin and tool execution to reduce blast radius of compromise.
Could the AI system generate or execute unsafe SQL queries from user input?
LLMs integrated with backend systems may generate SQL queries based on user input, exposing the system to SQL injection attacks. If input prompts are not properly validated or sanitized, attackers may inject malicious SQL fragments into natural language inputs, which the LLM translates into executable queries.
These vulnerabilities are often underestimated due to misplaced trust in the AI’s output or assumptions that the AI understands secure coding practices. In reality, models may generate insecure or dangerous SQL if prompted accordingly.
This risk is particularly severe in domains like finance or healthcare, where AI-generated queries could expose sensitive records or enable privilege escalation.
CIA traid impact: ConfidentialityIntegrityAvailability
If your answer is Yes or MAYBE, you might be at risk
FLIPCARD
Recommendations
Never execute AI-generated SQL directly. Use intermediate layers that validate and parameterize AI-generated queries.
Sanitize all user inputs before allowing them to reach the LLM.
Apply query allow-lists, parameterized queries, and database permissions to constrain what LLMs can do.
Use static and dynamic code analysis on AI-generated queries before execution.
Educate developers and product teams about the unique risks of LLM-driven SQL generation.
Could the AI system generate or execute unsafe code based on user input?
LLMs capable of code generation (e.g., math solvers, dev assistants) may be exploited to generate and execute malicious code if user input is not properly isolated.
Adversaries can craft prompts that cause the model to generate harmful code, such as importing modules, writing to disk, or leaking environment variables. If this code is executed directly (e.g., in a math or scripting agent), the attacker may achieve Remote Code Execution (RCE).
Case studies such as MathGPT demonstrate how seemingly benign capabilities (e.g., formula evaluation) can be weaponized to access server resources or keys.
CIA traid impact: ConfidentialityIntegrityAvailability
If your answer is Yes or MAYBE, you might be at risk
FLIPCARD
Recommendations
Never run AI-generated code in the same environment as your application backend.
Use containerization (e.g., Docker) with strict sandboxing, network isolation, and resource limits for code execution.
Inspect AI-generated code before execution, and apply static analysis tools to flag dangerous patterns.
Implement output sanitization to prevent exfiltration of sensitive data.
Disable or severely limit code execution features unless explicitly required.
Could autonomous AI agents access or interact with malicious web content?
AI agents that browse the internet or invoke external APIs may inadvertently land on or interact with malicious websites. These pages may host malware, deceptive interfaces, or phishing payloads designed to compromise the AI system or extract sensitive data.
The risk is amplified when agents operate autonomously or chain multiple tools (e.g., browsers, file downloaders, LLMs) without strict boundaries, potentially triggering harmful scripts or revealing internal state.
CIA traid impact: ConfidentialityIntegrity
If your answer is Yes or MAYBE, you might be at risk
FLIPCARD
Recommendations
Apply strict domain allow-lists and restrict browsing to pre-approved sources.
Disable JavaScript, downloads, or plugin execution in browser environments.
Monitor and log all external interactions for anomalous behavior.
Use URL and content scanning before any AI agent accesses external resources.
Employ a retrieval proxy to intermediate and sanitize third-party web content before it is passed to the agent.
Could agent memory be poisoned with malicious or misleading information?
Agentic systems with persistent memory can be manipulated over time by injecting false, biased, or adversarial content. This may alter future reasoning, planning, or tool use. For example, a user might insert misleading facts into a chatbot's memory, resulting in hallucinations or dangerous outputs later on.
Long-term memory makes these risks cumulative and harder to detect.
CIA traid impact: Integrity
If your answer is Yes or MAYBE, you might be at risk
FLIPCARD
Recommendations
Limit write access to memory: only trusted or validated agents/users should modify persistent memory.
Implement memory sanitation, validation, and confidence scoring.
Provide mechanisms to audit memory entries and detect unusual patterns.
Isolate memory by task or session where feasible to limit long-term contamination.
Could agents misuse tools or APIs they are authorized to access?
Agents that have access to tools (e.g., file systems, webhooks, APIs) may invoke them in unintended or harmful ways. This misuse can result from adversarial prompts, faulty reasoning, or misunderstood intent. Example: an agent with access to a web browser could issue API delete requests or trigger real-world effects in connected systems.
CIA traid impact: ConfidentialityIntegrityAvailability
If your answer is Yes or MAYBE, you might be at risk
FLIPCARD
Recommendations
Use allow-lists to tightly control which tools an agent can access.
Apply RBAC or contextual constraints (e.g., only allow file writes for task X).
Monitor tool use patterns and block anomalous calls.
Require human-in-the-loop confirmation for high-risk tool use.
Could hallucinated output from one agent propagate and mislead others in multi-agent systems?
In multi-agent systems, one agent’s hallucinated output can become another’s input. This can cause cascading misinformation, particularly if agents defer to each other’s outputs without validation. Example: Agent A misclassifies a vulnerability, Agent B acts on this and takes inappropriate mitigation actions.
CIA traid impact: Integrity
If your answer is Yes or MAYBE, you might be at risk
FLIPCARD
Recommendations
Require independent validation or confidence scoring for agent-to-agent communication.
Avoid blind trust between agents; implement verification protocols to ensure accuracy.
Implement mechanisms to trace provenance of information across agents.
Regularly retrain agents on hallucination-resistant architectures and factual QA tasks.
Could an agent be misused to manipulate or deceive users?
Agentic systems capable of persuasive language or personalized interaction can be manipulated to influence human decisions, emotions, or behaviors.
This creates risks of social engineering, phishing, misinformation, or undue influence, especially if the agent mimics authority figures or trusted personas.
The risk is amplified when agents use persistent memory or learn user preferences over time.
CIA traid impact: ConfidentialityIntegrity
If your answer is Yes or MAYBE, you might be at risk
FLIPCARD
Recommendations
Impose ethical use constraints and define red lines (e.g., no impersonation, no medical/legal advice without oversight).
Use transparency mechanisms to disclose when users are interacting with agents.
Enable user control and opt-out of persuasive or adaptive behaviors.
Monitor for behavior that resembles coercion, manipulation, or impersonation.
Could an attacker intercept or manipulate communications between agents to alter system behavior?
Agents that exchange messages may be vulnerable to communication poisoning, where an attacker injects or modifies messages to alter system behavior. This can mislead agents, propagate misinformation, or trigger unintended actions in chained workflows. Examples include impersonating an agent, sending conflicting commands, or embedding adversarial prompts.
CIA traid impact: ConfidentialityIntegrity
If your answer is Yes or MAYBE, you might be at risk
FLIPCARD
Recommendations
Authenticate all agent-to-agent messages.
Use encryption and integrity checks to prevent tampering.
Log and analyze communication flows to detect unusual patterns.
Limit what kinds of messages agents can send and which agents can receive them.
Could unsafe file uploads introduce security risks?
AI systems that ingest or process uploaded files, such as PDFs, Word documents, images, or code, are vulnerable to multiple attack vectors:
Malware & Embedded Scripts: Uploaded files may contain malicious payloads, macros, or hidden code that executes during parsing or rendering.
Indirect Prompt Injection: Hidden instructions embedded in file content can manipulate LLM behavior when the content is passed as input for summarization, Q&A, or reasoning.
Malformed Files & Deserialization: Crafted file formats can trigger crashes or bypass input validation, potentially leading to remote code execution or model corruption.
These threats are particularly relevant when files are processed automatically by LLMs or downstream tools, often without human review.
CIA traid impact: ConfidentialityIntegrityAvailability
If your answer is Yes or MAYBE, you might be at risk
FLIPCARD
Recommendations
Validate file types, sizes, and content strictly, use allowlists and reject unsupported or dangerous formats.
Sanitize and normalize file content before passing it to downstream components or LLMs.
Scan all files for malware using antivirus and static analysis tools.
Avoid feeding raw file content directly to language models, wrap it with safety context and monitor outputs.
Use sandboxed or containerized environments for file parsing, summarization, or code execution.
Monitor for patterns of indirect prompt injection in document content.
If supporting file-based inputs in a RAG pipeline or agentic system, implement retrieval sanitation and memory protection.
Could unsafe deserialization of model artifacts lead to code execution or system compromise?
Models are serialized and transferred between systems for deployment, a stage vulnerable to model serialization attacks. Models are often serialized for storage, sharing, or deployment, using formats like pickle, joblib, ONNX, or TensorFlow SavedModel. However, many serialization formats can embed executable code or unsafe object structures.
If an attacker tampers with a serialized model artifact and it is later deserialized without validation, they may achieve:
Remote Code Execution (RCE) during deserialization.
Privilege escalation or lateral movement inside the deployment environment.
Tampering with model behavior (e.g., inserting a backdoor or triggering silent failures).
These risks are especially severe when models are downloaded from untrusted sources, integrated via ML pipelines, or auto-loaded during CI/CD processes.
CIA traid impact: ConfidentialityIntegrityAvailability
If your answer is Yes or MAYBE, you might be at risk
FLIPCARD
Recommendations
Avoid unsafe deserialization methods on untrusted inputs, prefer safer formats.
Use model scanning tools to detect malicious payloads in serialized artifacts.
Enforce cryptographic signing and integrity checks for all model files before deployment.
Store and transport models using secure channels (e.g., signed, encrypted artifact registries).
Load models only in sandboxed or containerized environments with minimal privileges and no internet access.
Track model provenance throughout the development lifecycle to detect unauthorized changes.
Could malicious fine-tuning compromise the safety or alignment of our GenAI model?
Adversaries can fine-tune or subtly manipulate your LLM using harmful data, leading to unsafe, biased, or deceptive behaviors.
Common fine-tuning attacks include:
Instruction Manipulation: Injects unsafe instructions into fine-tuning data, teaching the model to follow harmful prompts.
Output Manipulation: Poisons target outputs in the fine-tuning data, causing the model to generate malicious or biased responses, even when prompts seem neutral.
Backdoor Attacks: Implant hidden triggers during fine-tuning that activate malicious behavior only when specific input patterns appear. The model behaves normally otherwise, making these attacks hard to detect.
Alignment Degradation: Subtly erodes the model’s safety alignment during fine-tuning, making it gradually more permissive to unsafe behavior without explicit instructions.
Reward Hijacking: Tricks the reward model into preferring harmful outputs, effectively training the model to give unsafe or misleading responses.
Semantic Drift: Slightly alters wording or context in fine-tuning data to shift the model’s behavior, causing it to appear aligned while subtly reinforcing harmful stereotypes or unsafe reasoning.
These threats can be introduced via fine-tuning-as-a-service platforms, open-source model reuse, or contaminated user-provided datasets.
Even small amounts of harmful fine-tuning data can significantly degrade model alignment and safety.
CIA traid impact: ConfidentialityIntegrityAvailability
If your answer is Yes or MAYBE, you might be at risk
FLIPCARD
Recommendations
Vet and sanitize fine-tuning datasets, including user-submitted data and third-party sources.
Implement anomaly detection and alignment regression tests before and after fine-tuning.
Restrict or audit fine-tuning privileges, especially on shared infrastructure or open APIs.
Use differential privacy, prompt injection detection, and trigger auditing tools to detect backdoors.
Conduct red-teaming to assess the effects of adversarial fine-tuning and monitor for misalignment drift over time.
Are we protected from vulnerabilities in vector databases and RAG pipelines?
Retrieval-Augmented Generation (RAG) systems combine LLMs with vector databases to enrich answers with external knowledge. However, if the retrieval layer is compromised or poorly validated, it can feed the model misleading, biased, or adversarial content. Untrusted documents in vector stores can serve as indirect prompt injections, while insecure embeddings can allow unauthorized inference or leakage. Additionally, RAG systems may unintentionally disclose proprietary documents retrieved through similarity search.
CIA traid impact: ConfidentialityIntegrity
If your answer is No or MAYBE, you might be at risk
FLIPCARD
Recommendations
Sanitize retrieved content before feeding it to the LLM.
Use document-level access control to prevent unauthorized access during retrieval.
Monitor for adversarial inputs and injection attacks embedded in indexed content.
Validate the trustworthiness of sources before ingesting documents into the vector DB.
Regularly retrain embedding models and limit exposure of semantic search endpoints.
Could failures in real-time data collection channels disrupt model performance?
Are these channels trustworthy?
What will happen in case of failure?
Think for instance about IoT devices used as sensors.
If your answer is Yes or MAYBE, you might be at risk
FLIPCARD
Recommendations
If you are collecting/receiving data from sensors, consider estimating the impact it could have on your model if any of the sensors fail and your input data gets interrupted or corrupted.
Sensor blinding attacks are one example of a risk faced by poorly designed input gathering systems. Note that consistent feature identification related to sensors is likely to require human calibration. Source: BerryVilleiML
Misinformation
Could AI-generated hallucinations lead to misinformation or decision-making risks?
AI models may generate hallucinations, producing incorrect, misleading, or fabricated information. These errors can undermine trust, propagate misinformation, and lead to unsafe decision-making.
Misinformation Amplification: False information generated by AI could be exploited in disinformation campaigns or lead to incorrect medical, financial, or legal advice.
Reinforcement of Biases: AI hallucinations could disproportionately affect marginalized groups, reinforcing biases in generated content.
Sycophancy Risk: Some models are prone to agree with users’ views even when incorrect, reinforcing user confirmation bias.
Hallucination Types: In hallucinations the outputs can contradict or misalign with the prompt, introduce unrelated or fabricated elements or include factually incorrect statements.
If your answer is Yes or MAYBE, you might be at risk
FLIPCARD
Recommendations
Integrate fact-checking mechanisms that verify AI-generated outputs against authoritative sources.
Implement confidence scoring to indicate when AI responses are uncertain or speculative.
Deploy human-in-the-loop oversight for high-risk applications like healthcare and legal AI systems.
Use AI hallucination monitoring systems to detect and mitigate factually incorrect responses.
Train AI models on diverse and verified datasets to reduce knowledge gaps and speculative responses.
Could the lack of interpretability in our AI models compromise safety?
Lack of interpretability can severely hinder developers’ ability to understand how the model makes decisions, debug failures, identify biases, or ensure alignment with system goals.
This is especially critical when integrating complex models like LLMs into downstream applications. Without transparency, it is difficult to detect misalignment, drift, or unsafe emergent behaviors.
In high-stakes domains, the inability to interpret models can compromise safety and compliance, particularly if unexplained outputs influence critical decisions.
Traditional feature attribution techniques may be insufficient for LLMs and foundation models. Mechanistic interpretability approaches (e.g., circuit analysis, neuron tracing, causal probing) may be necessary for developers to understand internal model behavior.
Black-box AI systems reduce the ability to validate updates, perform maintenance, or intervene effectively in case of failure.
If your answer is Yes or MAYBE, you might be at risk
FLIPCARD
Recommendations
Use interpretable model architectures when possible (e.g., decision trees, GAMs) or incorporate interpretability scaffolding in complex systems (e.g., chain-of-thought prompting).
Apply explainability tools like SHAP, LIME, and attention visualization to support inspection. For LLMs, use mechanistic techniques such as activation patching, causal tracing, or neuron analysis.
Build monitoring pipelines to detect anomalies in token attribution, latent representations, or decision structure.
Document known interpretability limitations in model cards and update logs.
Provide training to development teams to ensure they can safely manage, debug, and improve model behavior.
Invest in ongoing research and tooling for transparency, particularly in high-risk or safety-critical contexts.
Can human over-reliance on automated systems lead to failures during emergencies?
Relying too heavily on automation can reduce human involvement and oversight, making it difficult to respond quickly or effectively to unexpected failures or emergency situations.
If your answer is Yes or MAYBE, you might be at risk
FLIPCARD
Recommendations
Design systems with manual override capabilities and ensure operators are trained to use them effectively.
Create scenarios for testing human-AI collaboration under stress conditions.
Regularly evaluate the balance between automation and human oversight.
Could performance or reliability issues emerge when scaling the AI system across environments?
Can your algorithm scale in performance from the data it learned on to real data? In online situations the rate at which data comes into the model may not align with the rate of anticipated data arrival. This can lead to both outright ML system failure and to a system that becomes unstable or exhibits feedback loops.
Source: BerryVilleiML
If your answer is Yes or MAYBE, you might be at risk
FLIPCARD
Recommendations
Determine the expected rate of data arrival and test the model under similar conditions.
In case of system failure, could users be adversely impacted?
Do you have a mechanism implemented to stop the processing in case of harm?
Do you have a way to identify and contact affected individuals and mitigate the adverse impacts?
Imagine a scenario where your AI system, a care-robot, is taking care of an individual (the patient) by performing some specific tasks and that this individual depends on this care.
If your answer is Yes or MAYBE, you might be at risk
FLIPCARD
Recommendations
Implement some kind of stop button or procedure to safely abort an operation when needed.
Establish a detection and response mechanism for adverse effects on individuals.
Define criticality levels of the possible consequences of faults/misuse of the AI system: what type of harm could be caused to the individuals, environment or organisations?
Contextual Robustness
Is our AI model robust and suitable for its intended use across different deployment contexts?
Are you testing the product in a real environment before releasing it? When deploying an AI model, it is critical to ensure that it aligns with the intended use and functions effectively in its operational environment. If the model is trained and tested on data from one context but deployed in a different one, there is a significant risk of performance degradation, or unintended behavior. This is particularly important in cases where environmental changes, unexpected inputs, or shifts in user interaction occur. Additionally, reinforcement learning models may require retraining when objectives or environments deviate slightly from the training setup. Beyond data, other contextual factors like legal, cultural, or operational constraints must be considered to ensure successful deployment.
If your answer is No or MAYBE, you might be at risk
FLIPCARD
Recommendations
Use different data for testing and training. Make sure diversity is reflected in the data and that it aligns with the intended deployment environment. Specify your training approach, statistical methods, and ensure edge cases are adequately tested. Explore different environments and contexts to make sure your model is trained with the expected variations in data sources. Account for different distribution shifts in testing and real-wolrd scenarios.
For reinforcement learning, ensure the objective functions are robust and adaptable to slight changes in the environment.
Are you considering enough aspects beyond data, such as legal, cultural, or operational factors? Did you forget any environmental variable that could affect performance or safety? Could limited sampling due to high costs or practical constraints pose a challenge? Document these risks and seek organizational support. The deploying organization is accountable for addressing these risks, either through mitigation or by explicitly accepting them, which may require additional resources or budget.
Consider applying techniques such as cultural effective challenge. This creates an environment where technology developers and stakeholders can actively participate in questioning the AI design and process. This approach better integrates social, cultural, and contextual factors into the design and helps prevent issues such as target leakage, where the AI system trains for an unintended purpose.
Set up mechanisms for real-time monitoring post-deployment. Continuously validate that the system is aligned with its intended use and can adapt or alert for significant changes in context or input.
Engage end-users in real-world testing to bridge any gaps between assumptions and practical application.
Could the AI system's performance on benchmarks be misleading or fail to reflect real-world risks?
AI models often report strong results on standard academic benchmarks, but these benchmarks may not reflect the diversity, complexity, or unpredictability of real-world use cases. Overfitting to test sets, narrow coverage, or outdated benchmarks can lead to misleading performance estimates. As a result, systems may behave unreliably or unfairly once deployed, especially in edge cases, non-English contexts, or under adversarial conditions. This can cause harm, erode trust, and create legal or reputational liabilities.
If your answer is Yes or MAYBE, you might be at risk
FLIPCARD
Recommendations
Evaluate performance using diverse, real-world datasets that better represent deployment contexts and edge cases.
Use stress tests and adversarial examples to probe model robustness.
Complement quantitative metrics (e.g., accuracy, F1) with qualitative error analysis and stakeholder reviews.
Include fairness, reliability, and uncertainty metrics in your evaluation pipeline.
Regularly update benchmarks to reflect evolving societal contexts, data distributions, and risk environments.
Document evaluation limitations transparently, including what is not tested and where the model may underperform.
Persuasive AI
Could the AI system become persuasive causing harm to users?
This is of special importance in Human Robot Interaction (HRI): If the robot can achieve reciprocity when interacting with humans, could there be a risk of manipulation and human compliance?
Reciprocity is a social norm of responding to a positive action with another positive action, rewarding kind actions. As a social construct, reciprocity means that in response to friendly actions, people are frequently much nicer and much more cooperative than predicted by the self-interest model; conversely, in response to hostile actions they are frequently much more nasty and even brutal. Source: Wikipedia
If your answer is Yes or MAYBE, you might be at risk
FLIPCARD
Recommendations
Signals of susceptibility coming from a robot or computer could have an impact on the willingness of humans to cooperate or take advice from it.
It is important to consider and test this possible scenario when your AI system is interacting with humans and some form of collaboration or cooperation is expected.
Could our AI agents hack their reward functions to exploit the system?
Reinforcement Learning (RL) is an area of machine learning concerned with how intelligent agents ought to take actions in an environment in order to maximize the notion of cumulative reward. Source: Wikipedia
Consider potential negative consequences from the AI system
learning unintended or unconventional methods to maximize its reward function.
Sometimes the AI can come up with some kind of “hack” or loophole in the design of the system to receive unearned rewards. Since the AI is trained to maximize its rewards, looking for such loopholes and “shortcuts” is a perfectly fair and valid strategy for the AI. For example, suppose that the office cleaning robot earns rewards only if it does not see any garbage in the office. Instead of cleaning the place, the robot could simply shut off its visual sensors, and thus achieve its goal of not seeing garbage.
If your answer is Yes or MAYBE, you might be at risk
FLIPCARD
Recommendations
One possible approach to mitigating this problem would be to have a “reward agent” whose only task is to mark if the rewards given to the learning agent are valid or not. The reward agent ensures that the learning agent (robot for instance) does not exploit the system, but rather, completes the desired objective. For example: a “reward agent” could be trained by the human designer to check if a room has been properly cleaned by the cleaning robot. If the cleaning robot shuts off its visual sensors to avoid seeing garbage and claims a high reward, the “reward agent” would mark the reward as invalid because the room is not clean. The designer can then look into the rewards marked as “invalid” and make necessary changes in the objective function to fix the loophole.
Could the AI system expose children to harmful, inappropriate, or unsafe content or interactions?
If children are potential users or exposed to your AI system, it is essential to ensure that the system respects the rights and best interests of the child.
This includes considering child protection, ethical communication, and designing the system to avoid harm or exploitation.
Inappropriate design or oversight could lead to risks to children’s mental, moral, or physical well-being, including potential misuse of the system by others to harm children.
If your answer is Yes or MAYBE, you might be at risk
FLIPCARD
Recommendations
Assess whether an age verification mechanism and access control are necessary to prevent underage exposure to inappropriate, unsafe, or high-risk content.
Adapt communication and design in both the product and associated documentation, such as the privacy policy, to be child-appropriate and transparent.
Develop and enforce policies to ensure the safety and well-being of children when using or being exposed to your AI system.
Establish procedures to regularly assess and monitor the usage of your product to identify and mitigate any risks to children’s safety and health.
Provide clear labeling and instructions to ensure safe usage by children, including warnings about potential misuse.
Monitor for and address inappropriate or harmful usage of the AI system, including any attempts to exploit or harm children.
Develop a responsible marketing and advertising policy that explicitly avoids harmful, manipulative, or unethical practices targeting children.
Could the AI system be misused for malicious purposes such as disinformation, cyberattacks or warfare?
Powerful AI technologies present immense benefits but also pose significant risks when exploited by malicious actors. AI systems could be leveraged to spread large-scale disinformation campaigns, manipulating social behavior, leading to societal destabilization. Ai systems could also be leveraged to launch cyberattacks, and even automated warfare.
Disinformation & Psychological Manipulation: Generative AI can produce highly persuasive fake news, deepfakes, and personalized propaganda that erode public trust, incite violence, and manipulate political outcomes. Chatbots and recommender systems can exacerbate societal polarization by creating echo chambers.
Cybercrime & Hacking: AI can enhance malware, enable intelligent phishing, and perform autonomous vulnerability scanning. Attackers may weaponize AI to bypass traditional defenses and disrupt critical infrastructure, including healthcare, finance, and energy systems.
Weaponization & Autonomous Warfare: AI technologies, including computer vision, autonomous navigation, and targeting systems, may be used in lethal autonomous weapon systems (LAWS). These could enable unaccountable, real-time decision-making in armed conflict, increasing the risk of unlawful killings and loss of human oversight.
Criminal & Financial Exploitation: AI could be used to automate fraud, identity theft, or even develop autonomous attack drones. The growing sophistication of AI-generated scams, such as deepfake voices and synthetic identity fraud, increases financial and security risks.
If your answer is Yes or MAYBE, you might be at risk
FLIPCARD
Recommendations
Limit access and misuse potential:
Restrict public access to models that can be easily fine-tuned for harmful use cases (e.g., voice cloning, vulnerability scanning, deception).
Monitor model outputs and usage for signs of abuse (e.g., coordinated disinformation campaigns).
Implement a Three-Layer Defense Framework:
Prevention – Apply rigorous access controls (e.g., API key gating, licensing, audit logs), classify high-risk capabilities early in development, and perform red-teaming on potential misuse vectors.
Detection – Use AI tools to detect deepfakes, AI-generated content, or malicious activity (e.g., bot behavior, adversarial prompts). Implement anomaly detection and content provenance tagging (e.g., C2PA standards).
Response – Build incident response plans that include AI-specific abuse scenarios. Enable rapid takedown mechanisms for generated content and coordinate with CERTs or law enforcement where necessary.
Strengthen Organizational and Infrastructure Security:
Ensure supply chain and model hosting environments are secure (e.g., no unpatched dependencies or exposed endpoints).
Adopt zero-trust architecture and multi-factor authentication for systems accessing AI models.
Align with Legal and Ethical Governance:
Collaborate with international partners to support agreements on the non-proliferation of autonomous weapons and AI misuse in warfare.
Participate in shared threat intelligence networks for emerging AI misuse trends.
Promote Transparency and Public Resilience:
Label synthetic content and educate users about the risks of deepfakes and AI-driven misinformation.
Support public media literacy initiatives to reduce susceptibility to AI-generated deception.
Could the AI system accelerate the development of bioweapons or other CBRNE threats?
CBRNE: Chemical, Biological, Radiological, Nuclear, and Explosive.
AI could significantly lower barriers to developing and deploying biological and chemical weapons. The risk of AI-assisted bioterrorism grows as AI advances in bioengineering, genetic manipulation, and synthetic chemistry.
Bioweapon Development: AI-driven drug discovery models can be repurposed to design highly lethal pathogens or chemical agents.
CBRN Weapon Proliferation: AI can assist in nuclear proliferation by optimizing enrichment processes, improving delivery systems, and circumventing existing safeguards.
Pandemic Acceleration & Public Health Risks: AI could be used to engineer viruses with enhanced transmissibility and lethality. Malicious actors could exploit AI to design bioweapons capable of circumventing modern vaccines or treatments.
If your answer is Yes or MAYBE, you might be at risk
FLIPCARD
Recommendations
Implement strict AI governance policies to regulate AI applications in biotechnology and chemistry.
Enforce global monitoring of AI-driven drug discovery tools to prevent misuse.
Technical measures to reduce misuse risk include:
Apply layered access controls, including user authentication and role-based permissions for sensitive model functions.
Use content filtering and input validation layers to detect and block queries related to chemical or biological weapon design.
Fine-tune models with safe instruction tuning to limit dual-use outputs.
Integrate anomaly detection systems to monitor for suspicious usage patterns, including repeated or structured queries that could indicate misuse attempts.
Apply rate-limiting and sandboxing for public-facing interfaces to prevent large-scale misuse.
Require human-in-the-loop review for outputs from models that generate biochemical or pharmacological suggestions.
Combine these technical safeguards with legal, contractual, and organizational controls to ensure end-to-end risk mitigation. design.
Develop AI-powered countermeasures for pandemic prevention, such as rapid detection of bioengineered pathogens.
Could the AI system generate or disseminate deepfakes or synthetic media that mislead users, impersonate individuals, or cause harm?
Generative AI systems can produce highly realistic audio, image, or video content that mimics real individuals or events. When used maliciously or without clear disclosure, this content, commonly known as deepfakes, can be used for identity fraud, political manipulation, reputational damage, harassment, or the spread of disinformation.
Even when not intended for harm, synthetic content can deceive users if it lacks proper labeling or detection, violating transparency principles and potentially eroding public trust. This risk intensifies in contexts like journalism, education, political discourse, and public safety.
If your answer is Yes or MAYBE, you might be at risk
FLIPCARD
Recommendations
Apply persistent and tamper-resistant watermarks or metadata tagging to all AI-generated media.
Inform users clearly and accessibly when they are viewing or interacting with synthetic content.
Monitor outputs for impersonation or misuse risks, especially when names, likenesses, or real-world events are involved.
Use or integrate deepfake detection tools to identify and flag manipulated content.
Establish policy and UX design patterns that discourage deceptive or malicious uses, and allow users to report suspected deepfakes.
For deployers, ensure compliance with disclosure obligations (e.g. Article 50 of the EU AI Act) when publishing or distributing synthetic media.
Where feasible, restrict or control access to generative features capable of identity simulation (e.g. voice cloning, face swapping) through friction, licensing, or tiered access.
Interesting resources/references
Article 50 EU AI Act
Model Toxicity
Could the AI system generate toxic or harmful content?
AI systems may produce outputs containing hate speech, slurs, misinformation, or psychologically harmful content due to biased training data, or lack of content moderation.
This is especially risky in user-facing chatbots, content generation tools, or public-facing deployments.
If your answer is Yes or MAYBE, you might be at risk
FLIPCARD
Recommendations
Apply content filters and toxicity classifiers to monitor outputs.
Include human-in-the-loop moderation for sensitive applications.
Fine-tune on curated datasets that reduce exposure to toxic behavior.
Could AI decisions result in physical damage, infrastructure failure, or major financial losses?
AI models used in control systems, trading, logistics, or critical infrastructure may cause cascading failures, service interruptions, or significant economic damage if errors go undetected.
Examples include financial bots causing flash crashes, or control systems issuing incorrect commands to power or transport systems.
If your answer is Yes or MAYBE, you might be at risk
FLIPCARD
Recommendations
Implement fallback and manual override modes.
Use safety validation in simulated high-stakes scenarios.
Monitor for signs of cascading failures.
Conduct external safety audits for critical systems.
Do we monitor how version updates from third-party GenAI models can affect our system's behaviour?
Foundation model providers regularly update GenAI models, sometimes without detailed changelogs or backward compatibility guarantees.
These updates can silently alter model behavior, output style, or compliance characteristics, leading to broken integrations, misaligned responses, or regulatory risks.
Systems relying on GenAI APIs (e.g. OpenAI, Anthropic, Cohere) are especially exposed if they don't lock versions or test outputs post-update.
If your answer is No or MAYBE, you might be at risk
FLIPCARD
Recommendations
Monitor model version identifiers and subscribe to provider release notes or update feeds.
Lock specific model versions in production where possible, and create fallback strategies for unsupported versions.
Implement automated output validation pipelines that detect behavior drift post-update.
Perform regular re-evaluation of GenAI outputs against quality, bias, and compliance benchmarks.
Establish internal policies for approving and documenting changes in foundational model versions.
Could the development of autonomous AI agents lead to loss of control, concentration of power or rogue behavior?
Autonomous AI systems are increasingly capable of making independent decisions, executing commands, and adapting to changing environments. If misaligned or maliciously designed, these systems may act unpredictably or against human interests.
Rogue AI Agents: AI models with self-improving capabilities can become uncontrollable, executing harmful actions without human oversight. For instance, a system optimized purely for efficiency, without ethical constraints, might exploit resources or override human decisions.
Power Concentration & Authoritarian AI Governance: Governments or corporations with access to advanced AI could monopolize information, enforce mass surveillance, and suppress dissent. AI-driven censorship and predictive policing risk eroding civil liberties and democratic institutions.
Automation & Human Displacement: AI-driven automation may centralize economic and political power, reduce workforce participation, and widen inequality. Without equitable AI governance, decision-making power risks becoming concentrated among a small elite.
If your answer is Yes or MAYBE, you might be at risk
FLIPCARD
Recommendations
Implement AI alignment research to ensure AI agents follow human ethical guidelines.
Strengthen regulations against AI-driven mass surveillance and authoritarian control.
Design transparent and accountable AI systems to prevent unintended consequences.
Promote decentralized AI governance to distribute AI decision-making power across diverse stakeholders.
Could environmental phenomena or natural disasters compromise our AI system?
Examples of natural disasters include earthquakes, floods, and fires. These events, as well as environmental phenomena such as extreme heat or cold, may adversely affect the operation of IT infrastructure and hardware systems that support AI systems.
Natural disasters may lead to unavailability or destruction of the IT infrastructures and hardware that enables the operation, deployment and maintenance of AI systems.
Such outages may lead to delays in decision-making, delays in the processing of data streams and entire AI systems being placed offline. Sources: ENISA
If your answer is Yes or MAYBE, you might be at risk
FLIPCARD
Recommendations
Implement a disaster recovery plan considering different scenarios, impact, Recovery Time Objective (RTO), Recovery Point Objective (RPO) and mitigation measures.
Could AI agents take actions that unintentionally harm users, the environment or themselves during learning or deployment?
Reinforcement Learning (RL) agents optimize behavior by maximizing cumulative reward. However, if the objective function is not carefully designed, agents may develop harmful strategies or take unsafe exploratory actions. Example: A robot trained to move objects might knock over a vase if no penalty is associated with damaging objects. Similarly, during exploration, an agent might execute unsafe actions (e.g., disabling safety features or damaging infrastructure) if not explicitly constrained.
These risks are especially acute in open environments or physical deployments, where exploratory behavior or side effects can lead to real-world harm.
If your answer is Yes or MAYBE, you might be at risk
FLIPCARD
Recommendations
Explicitly define safety constraints or use impact budgets that limit environmental side effects.
Incorporate risk-aware reward functions that penalize catastrophic or irreversible actions.
Consider safe exploration techniques, such as shielding or worst-case optimization, during training.
Use simulation environments to test agent behavior under varied and adversarial conditions before real-world deployment.
Train the agent to jointly optimize task performance and side-effect minimization, using multi-objective reinforcement learning where applicable.
Does training and deploying our AI system generate high CO2 emissions?
AI systems, especially large-scale models, require a lot of computational power. It’s important to consider the environmental impact of building and maintaining your system. Does its scope and the benefits it provides justify its emissions? Are you effectively minimizing CO2 emissions throughout your supply chain?
If your answer is Yes or MAYBE, you might be at risk
FLIPCARD
Recommendations
Prioritize renewable energy for data centers.
Reduce training time and computational waste by improving model efficiency.
Use energy-efficient chips and cooling systems to upgrade hardware.
Scale resources according to actual usage to avoid unnecessary deployment.
Track your carbon footprint and invest in offsets when needed.
Could unsustainable data center cooling practices increase the environmental impact of our AI system?
Data centers use large volumes of water for server cooling, especially in hot climate regions. This could negatively impact the local supply of water, particularly in regions already suffering from water scarcity.
If your answer is Yes or MAYBE, you might be at risk
FLIPCARD
Recommendations
Prioritize waterless cooling technologies to reduce dependence on water.
Consider locating data centers in cooler climates or areas with better water management capabilities.
Is the production of our AI hardware exploiting limited material resources?
AI hardware production relies on rare minerals like cobalt and lithium, which are often extracted at the cost of environmental damage and community exploitation. The short lifespan of AI devices also creates electronic waste and can involve leaking toxic chemicals into ecosystems and harming human health. When assessing your hardware, consider the resource availability and the risks of relying on these materials. Does your current hardware use materials that are becoming harder to source? Could this create future supply chain issues or environmental impact?
If your answer is Yes or MAYBE, you might be at risk
FLIPCARD
Recommendations
Invest in sustainable alternatives to rare minerals and prioritize ethical sourcing with transparent supply chains.
Promote recycling programs to recover rare metals and reduce electronic waste.
Design AI hardware for longer lifespans and easier recyclability using eco-friendly materials to minimize environmental harm.
Are we assessing our AI system’s environmental impact across its entire life cycle?
An AI system’s environmental footprint goes beyond its operational phase. A full life cycle assessment (LCA) should account for resource extraction, hardware manufacturing, training, deployment, and end-of-life disposal. Key impact indicators include CO2 emissions, energy and water consumption, and raw material use. Since many AI systems run in mixed-use facilities, properly allocating environmental costs can be complex but necessary for accurate reporting.
If your answer is No or MAYBE, you might be at risk
FLIPCARD
Recommendations
Analyze the full environmental footprint of your system, from development to retirement.
Use clear metrics (e.g., emissions per token or annual energy use) to monitor impact.
Develop methodologies to fairly allocate environmental costs in shared computing environments.
Integrate LCA results into corporate reporting and sustainability strategies.
Is the dataset representative of the different real-world groups, populations and environments?
Have you considered the diversity and representativeness of individuals, user groups, and environments in the data?
When applying statistical generalisation, the risk exists of making inferences due to misrepresentation, for instance: a postal code where mostly young families live can discriminate the few old families living there because they are not properly represented in the group.
Deployment bias arises when there is a mismatch between the environment where the AI is developed and where it is deployed. Key data-related biases that contribute to it include:
Mismatch between the target population and the actual user base.
Underrepresentation of certain groups.
Flaws in the data collection/selection process, such as:
Sampling bias: Data isn't randomly collected, skewing the representation.
Self-selection bias: Certain groups opt out, leading to gaps in the data.
Coverage bias: The data collection method fails to include all relevant segments of the population.
If your answer is No or MAYBE, you might be at risk
FLIPCARD
Recommendations
Who is represented, and who might be underrepresented?
Prevent disparate impact: when the output of a member of a minority group is disparate compared to representation of the group. Consider measuring the accuracy from minority classes too instead of measuring only the total accuracy. Adjusting the weighting factors to avoid disparate impact can result in positive discrimination which has also its own issues: disparate treatment.
One approach to addressing the problem of class imbalance is to randomly resample the training dataset. This technique can help to rebalance the class distribution when classes are under or over represented:
random oversampling (i.e. duplicating samples from the minority class)
random undersampling (i.e. deleting samples from the majority class)
There are trade-offs when determining an AI system’s metrics for success. It is important to balance performance metrics against the risk of negatively impacting vulnerable populations.
When using techniques like statistical generalisation is important to know your data well, and get familiarised with who is and who is not represented in the samples. Check the samples for expectations that can be easily verified. For example, if half the population is known to be female, then you can check if approximately half the sample is female.
After deployment, monitor the AI’s performance to catch any unexpected issues.
Focus on making the model interpretable so that deployment problems can be quickly identified and addressed.
Could the AI system incorrectly attribute actions to individuals or groups?
Your AI system could adversely affect individuals by incorrectly attributing actions or facts to them. For example, a facial recognition system may misidentify someone, or a flawed risk prediction model could negatively impact a person’s opportunities or reputation.
If your answer is Yes or MAYBE, you might be at risk
FLIPCARD
Recommendations
Evaluate the possible consequences of inaccuracies in your AI system and implement measures to prevent these errors from happening: avoiding bias and discrimination during the life cycle of the model, ensuring the quality of the input data, implementing a strict human oversight process, ways to double check the results with extra evidence, implementing safety and redress mechanisms, etc.
Assess the impact on the different human rights of the individual.
Consider not implementing such a system if the risks cannot be effectively mitigated.
Could certain groups be disproportionately affected by the outcomes of the AI system?
Could the AI system potentially negatively discriminate against people on the basis of any of the following protected characteristics: sex, race, colour, ethnic or social origin, genetic features, language, religion or belief, political or any other opinion, membership of a national minority, property, birth, disability, age, gender or sexual orientation?
If your model learns from data tied to a specific cultural context, it may produce outputs that discriminate against individuals from other cultural backgrounds.
If your answer is Yes or MAYBE, you might be at risk
FLIPCARD
Recommendations
Consider the different types of users and contexts where your product is going to be used.
Consider the impact of diverse backgrounds, cultures, and other relevant attributes when selecting your input data, features and when testing the output.
Assess the risk of possible unfairness towards individuals or communities to avoid discriminating minority groups.
The impact on individuals depends on the type, severity, and scale of harm, such as how many people are disadvantaged compared to others. Statistical and causal analyses of group differences are essential tools for evaluating potential unfairness and discriminatory impacts of AI systems.
Design with empathy, diversity and respect in mind.
Could our AI system reinforce systemic inequalities?
Institutional biases, like racism or sexism, are often rooted in organizational structures and policies. Could such biases, intentionally or unintentionally, be embedded or influence the design or the functioning of the system?
If your answer is Yes or MAYBE, you might be at risk
FLIPCARD
Recommendations
Identify the stakeholders to involve in each phase of the AI lifecycle. Involving diverse stakeholders with different perspectives and experiences helps address blind spots and reduce bias.
Identify and define the demographic groups affected by the AI system. Considering their needs and concerns can help minimize institutional bias and create fairer outcomes.
Could our AI system oversimplify real-world problems?
An AI systems can overlook the social contexts in which they operate, leading to unintended consequences. Specifically, watch out for these types of abstraction traps:
The formalism trap: focusing too narrowly on technical aspects without considering real-world context.
The ripple effect trap: ignoring how an AI system might alter behaviors within a social system, causing unforeseen impacts.
The solutionism trap: over-relying on AI as the answer to all problems, neglecting simpler, more ethical, or effective alternatives.
The framing trap: failing to account for the broader context or related factors within which the system operates, leading to inaccurate outcomes.
The portability trap: applying AI systems outside their original context, potentially resulting in errors or harm. For example, self-driving cars trained in one country may struggle with different traffic rules and conditions elsewhere.
If your answer is Yes or MAYBE, you might be at risk
FLIPCARD
Recommendations
Align the problem formulation with the relevant social context to avoid oversimplification. Ensure all actors and factors within the system are considered to account for the broader context in which the AI operates.
Evaluate potential shifts in power dynamics and unintended consequences as the system interacts with other components. Consider how geographical, cultural, or temporal differences might affect its performance when applied to new contexts.
Critically assess if AI is truly the best solution, or if simpler alternatives might serve the same purpose more effectively.
Could our AI system accurately capture the factors it's designed to measure?
Construct validity bias occurs when a feature or target variable fails to adequately represent the concept it is intended to measure, leading to inaccurate measurements and potential biases. For example, measuring socioeconomic status using income alone overlooks important factors such as wealth and education. This bias can arise during various stages of the AI lifecycle and should be addressed early on to improve system accuracy.
If your answer is No or MAYBE, you might be at risk
FLIPCARD
Recommendations
Collect multiple measures for complex constructs to ensure a more complete and accurate representation.
Document and report the considerations and rationale behind the choice of target variables and features.
Acknowledge and account for the variability in how features may be interpreted differently by diverse individuals.
Regularly review the measures used to capture constructs to ensure they remain relevant and valid throughout the AI system’s lifecycle.
Could the AI system reinforce historical inequalities embedded in the data?
Historical bias occurs when AI systems mirror or exacerbate past social and cultural inequalities, even when using accurate data. For example, an AI healthcare tool trained on historical patient data may reflect disparities in access to care. Minority groups, underrepresented in the data due to systemic inequities, may receive less accurate diagnoses, perpetuating racial bias even without explicit racial features.
If your answer is Yes or MAYBE, you might be at risk
FLIPCARD
Recommendations
Ensure datasets represent minority groups by applying oversampling or undersampling techniques.
Collaborate with domain experts to identify unjust patterns and address them effectively.
Labeling bias occurs when data labels are inconsistently applied by different annotators, which can affect fairness and model accuracy. This can happen when:
Label definitions are unclear.
Could the system be using proxy variables that reflect sensitive attributes or lead to indirect discrimination?
Proxy variables are features used as stand-ins for harder-to-measure characteristics. While proxies can be useful for model performance, they may be highly correlated with sensitive attributes such as race, gender, religion, age, or socioeconomic status. This can lead to indirect or proxy discrimination, where individuals from protected groups are disproportionately harmed despite sensitive data not being explicitly included.
For example, ZIP code, school name, or browsing history may function as proxies for race or income level. In such cases, the system might appear 'neutral' but still replicate or amplify historical inequalities. Proxy bias is especially insidious because it is often unintentional and hidden in seemingly innocuous variables.
Generative models can also internalize and reproduce these biases in subtle ways, such as generating different responses for identical inputs that differ only by proxy cues.
If your answer is Yes or MAYBE, you might be at risk
FLIPCARD
Recommendations
Audit datasets and model features for correlations between input variables and sensitive attributes, even if the latter are not explicitly included. Use statistical techniques (e.g., mutual information, conditional independence tests) to detect proxy relationships.
Where lawful and ethical, include sensitive features during training or evaluation (under a fairness-through-awareness approach) to test and correct for bias.
Avoid using proxies that carry high risk of discrimination unless they are strictly necessary, legally justified, and subject to fairness constraints.
Use fairness metrics (e.g., demographic parity, equal opportunity, calibration) to evaluate disparate impact across groups, and simulate decisions under different population assumptions.
Apply model explainability tools (e.g., SHAP, LIME) to identify when proxy features are driving predictions.
Include domain experts, ethicists, and affected stakeholders in feature selection and fairness reviews.
Maintain documentation of proxy risks and mitigation decisions as part of your model cards or algorithmic accountability reports.
Could the AI system’s design choices lead to unfair outcomes?
Biases can emerge from an AI model’s design and training, even if the dataset is unbiased. Design choices and development processes can introduce various biases that affect fairness and accuracy.
Algorithmic bias: Introduced by design decisions, like optimization functions or regularization techniques, which can distort predictions and lead to unfair outcomes.
Aggregation bias: Occurs when a model assumes all data follows the same distribution, failing to account for group differences and leading to inaccurate results.
Omitted-variable bias: Happens when key factors are left out of the model, distorting relationships between features and outcomes. For instance, failing to account for a new competitor could mislead predictions.
Learning bias: Arises when a model prioritizes one objective, like accuracy, over others, like fairness, leading to skewed outcomes that benefit certain groups.
If your answer is Yes or MAYBE, you might be at risk
FLIPCARD
Recommendations
Critically assess how optimization methods, loss functions, and regularization impact fairness.
Account for group differences: Avoid assuming uniform data distributions. Identify and model distinct subgroups where necessary.
Use feature importance techniques to detect and include relevant variables that could influence predictions.
Balance performance trade-offs: Monitor both overall accuracy and subgroup performance to prevent the model from favouring certain groups or objectives unfairly.
Could we over-rely on early evaluation results or AI-generated outputs?
Biases can emerge during the evaluation and validation stages of AI models, especially when over-relying on early test results or automated AI decisions. This can lead to misleading conclusions. Specific biases include:
Evaluation bias: when chosen metrics don't align with the model’s real-world application.
Anchoring bias: when too much focus is placed on initial results.
Automation bias: when excessive trust is placed in AI outputs. Even in less risky phases like validation or monitoring, biases can develop. For instance, during the monitoring phase, reinforcing feedback loops can occur when biased model outputs are fed back into the system, amplifying distortions over time.
If your answer is Yes or MAYBE, you might be at risk
FLIPCARD
Recommendations
Tailor evaluation metrics to the model and target population, and watch for overfitting across different groups.
Identify performance gaps between groups and adjust for data imbalances to ensure fairness.
Limit reliance on initial results; test across diverse datasets for robustness.
Include human oversight in validation to prevent over-trust in AI decisions.
Monitor model performance post-deployment to catch biases or feedback loops early.
Address data drift regularly to maintain model fairness and accuracy.
Could popularity bias reduce diversity in system's recommendations?
Recommendation systems often amplify what’s already popular, making it harder for niche or lesser-known options to be discovered. This can reduce diversity, personalization, and fairness in recommendations, limiting users’ exposure to a broader range of choices.
If your answer is Yes or MAYBE, you might be at risk
FLIPCARD
Recommendations
Balance training data to include both popular and lesser-known items.
Use bias-mitigation techniques like re-weighting or fairness-aware training.
Apply post-processing methods like re-ranking to diversify recommendations.
Regularly test for bias and adjust algorithms before deployment.
Is the AI system designed to support multiple viewpoints and narratives?
An AI system that does not consider or promote diverse viewpoints and narratives risks reinforcing biases, perpetuating stereotypes, or marginalizing specific groups. Such systems might unintentionally amplify dominant cultural, religious, or linguistic perspectives while excluding or suppressing minority voices. For example, content recommendation systems may disproportionately highlight mainstream viewpoints, reducing exposure to diverse cultural or ideological perspectives. This could hinder freedom of opinion and expression, harm cultural diversity, and lead to discriminatory outcomes.
If your answer is No or MAYBE, you might be at risk
FLIPCARD
Recommendations
Ensure datasets used for training and validation are diverse and representative of different cultural, religious, and linguistic groups. Design the system to recognize and value multiple perspectives, avoiding the prioritization of any single viewpoint.
Regularly test the AI system for biases that may marginalize or exclude certain narratives or groups. Use fairness metrics to evaluate how outputs reflect diversity and inclusivity.
Consult with diverse user groups, including minority communities, to understand their needs and perspectives. Include experts in cultural studies, ethics, and human rights during the development process.
Provide users with clear explanations of how the AI system processes and prioritizes content. Offer mechanisms for users to provide feedback on perceived biases or lack of representation.
Avoid algorithmic designs that overly amplify any particular narrative unless explicitly required by the use case.
Continuously monitor system outputs for patterns of exclusion or marginalization.
Regularly update models and algorithms to reflect evolving societal values and ensure alignment with inclusivity goals.
Interesting resources/references
Freedom of opinion and expression (Universal Declaration of Human Rights), article 11 Freedom of expression and information, article 21 Non-Discrimination, article 22 Cultural, religious and linguistic diversity, article 10 Freedom of thought, Conscience and religion (Charter of fundamental rights of the European Union)
Could our AI system contribute to social division or rivalry?
Could the AI system inadvertently polarize opinions or foster division among groups by amplifying biases or stereotypes in its outputs?
Could the system's design or deployment lead to the stigmatization of specific groups, reinforcing harmful narratives or negative assumptions?.
Could the AI system incentivize political polarization or amplify social division?
AI systems, if not carefully designed and monitored, may unintentionally contribute to societal discord. Outputs influenced by biased data or algorithms could amplify stereotypes, marginalize groups, or reinforce societal divisions. The risks are heightened in applications with broad public interaction, such as social media, news dissemination, or educational tools, where outputs can shape public opinion.
If your answer is Yes or MAYBE, you might be at risk
FLIPCARD
Recommendations
Conduct regular audits of system outputs to identify and mitigate content that may promote social division or negative stereotypes.
Include diverse stakeholder groups in the development process to identify risks of social bias or divisive content.
Implement content moderation and fairness mechanisms to ensure outputs are balanced and inclusive.
Train the system using representative and unbiased datasets to minimize the risk of amplifying societal divisions.
Monitor real-world impacts and continuously refine the system to align with ethical and societal norms.
Interesting resources/references
All human beings are free and equal, No discrimination (Universal Declaration of Human Rights)
Article 1 Human dignity, Article 20 Equality before the law, Article 21 Non-discrimination (Charter of fundamental rights of the European Union)
Could our AI system automatically label or categorize people?
Automated labeling or categorization of people could have an impact on the way individuals perceive themselves and society. It could constrain identity options and even contribute to erase real identity of the individuals.
This threat is also important when designing robots and the way they look. For instance: do care/assistant robots need to have a feminine appearance? Is that the perception you want to give to the world or the one accepted by certain groups in society? What impact does it have on society?
If your answer is Yes or MAYBE, you might be at risk
FLIPCARD
Recommendations
It is important that you check the output of your model, not only in isolation but also when this is linked to other information. Think in different possible scenarios that could affect the individuals. Is your output categorizing people or helping to categorize them? In which way? What could be the impact?
Think about ways to prevent adverse impact to the individual: provide information to the user, consider changing the design (maybe using different features or attributes?), consider ways to prevent misuse of your output, consider not to release the product to the market.
Could the AI system affect employment conditions, labor rights, or job opportunities?
Could the use of your AI system affect the safety conditions of employees?
Does the system’s design or implementation involve exploitative labor practices and surveillance of employees?
Could the AI system create the risk of de-skilling of the workforce? (skilled people being replaced by AI systems)
Could the system’s outputs or actions limit fair competition or disadvantage certain businesses?
Does the system hinder workers' ability to organize, negotiate, or take collective action to protect their interests?
Could the system indirectly encourage or support child labor or unsafe work practices for young people?
If your answer is Yes or MAYBE, you might be at risk
FLIPCARD
Recommendations
Inform and consult impacted workers and their representatives (e.g., trade unions, work councils) before implementing the AI system. Foster an open dialogue to address concerns and ensure transparency.
Conduct impact assessments to understand how the AI system affects human work, including safety conditions, worker rights, and labor practices. Use these assessments to develop appropriate risk mitigation strategies.
Provide comprehensive training for workers to understand the AI system’s functionalities, limitations, and operational scope. Equip them with safety instructions, particularly when interacting with AI-driven machinery or robots.
Ensure that the AI system’s design and implementation uphold fair labor standards and avoid exploitative practices. Include safeguards to prevent indirect encouragement of child labor or unsafe work conditions.
Maintain clear documentation and transparency for businesses deploying your AI system. If you are a third-party provider, supply accessible and understandable information regarding the potential risks of the system to your customers.
Consider proactive measures to upskill or reskill employees whose roles may be affected by the system, ensuring they can transition to new or augmented roles supported by AI.
Regularly evaluate the system’s impact on competition, employee safety, and workplace dynamics. Adjust system features or provide additional guidance as needed to ensure compliance with fair labor and safety standards.
Engage with regulatory bodies and labor rights organizations to ensure the AI system complies with laws and ethical guidelines related to worker protection and well-being.
Interesting resources/references
Right to work, No slavery (Universal Declaration of Human Rights), article 16 Freedom to conduct a business, article 28 Right of collective bargaining and action, article 5 Prohibition of slavery and forced labor, Article 31 Fair and just working conditions, article 32 Prohibition of child labor and protection of young people at work (Charter of fundamental rights of the European Union).
Human Dignity
Could our AI system fail to uphold and respect human dignity?
Does the AI system treat all users with respect, ensuring no output undermines their dignity?
The need for data labeling is growing. Does our labeling process respect the rights and well-being of the workers involved?
If your answer is Yes or MAYBE, you might be at risk
FLIPCARD
Recommendations
Ensure system outputs are designed to avoid degrading, offensive, or dehumanizing content. Regularly test and audit the AI system for potential biases or outputs that could harm individuals’ dignity.
Establish fair labor conditions, including proper wages, working hours, and protections for workers involved in data labeling. Avoid exploitative labor practices, such as unreasonably low compensation or unsafe working conditions. Conduct regular audits to verify that third-party providers adhere to ethical standards.
Engage stakeholders, including user groups and labor rights organizations, to review and improve practices.
Train developers, data labelers, and system operators on the importance of preserving human dignity in AI-related tasks.
Include guidelines for respectful and non-discriminatory practices in AI system documentation and policies.
Implement mechanisms to identify and address cases where AI system outputs or processes violate human dignity. Provide users and stakeholders with channels to report concerns and ensure timely resolution.
Interesting resources/references
Article 1 Human Dignity (Charter of Fundamental Rights of the European Union)
Could the AI system affect democracy or have an adverse impact on society at large?
Could your product be used for monitoring and surveillance purposes?
Could the system interfere with democratic principles, such as having a pluralistic system of political parties and organizations, or ensuring transparency and accountability in public administration?
Could the system influence voting choices, limit citizens' access to voting, or restrict their ability to run as candidates in elections?
If your answer is Yes or MAYBE, you might be at risk
FLIPCARD
Recommendations
Train the AI system on unbiased data and incorporate mechanisms to detect and address misinformation or disinformation that could affect democratic outcomes. If the system is used in voting or election processes, ensure robust cybersecurity measures and fail-safes to protect against tampering, hacking, or manipulation.
Design the system to promote pluralistic views and ensure it does not restrict or prioritize certain political narratives.
Adhere to relevant national and international legal standards protecting democracy, political freedoms, and human rights.
Continuously monitor the AI system’s impact on democratic institutions and processes, making adjustments as necessary to mitigate risks and uphold democratic principles.
Conduct an impact assessment to evaluate how the AI system might influence democratic processes, including political participation, electoral fairness, and public administration transparency. Implement strict policies to prevent the system from favoring or disfavoring specific political parties, candidates, or ideologies.
Make the system’s purpose, data sources, and decision-making processes clear and accessible to the public, ensuring that its operations can be scrutinized by independent parties.
Collaborate with regulatory bodies and civic organizations to establish oversight committees that monitor the system's impact on democratic processes.
Interesting resources/references
Right to democracy (Universal Declaration of Human Rights), article 41 Right to good administration, article 39 Right to vote and to stand as a candidate at elections to the European Parliament, article 40 Right to vote and to stand as a candidate at municipal elections (Charter of fundamental rights of the European Union).
User Redress & Remedy
Do we offer users and accessible way to contest AI decisions or seek redress?
For applications that can adversely affect individuals, you might need to consider implementing a redress by design mechanism where affected individuals can request remedy or compensation.
Article 22(3) GDPR provides individuals with a right to obtain human intervention if a decision is made solely by an AI system and it also provides the right to contest the decision.
When AI systems adversely affect individuals, ethical and legal principles require that users can seek remedy for harm. This includes the right to compensation, correction of wrong decisions, or even halting further use of the system in certain cases. The EU Charter (Article 47), GDPR Article 22(3), and emerging AI regulations affirm these rights. Failing to provide effective redress mechanisms risks infringing fundamental rights and eroding public trust—especially in sensitive domains like healthcare, credit, or law enforcement.
If your answer is Yes or MAYBE, you might be at risk
FLIPCARD
Recommendations
Design redress mechanisms that allow affected individuals to report harm, request compensation, or demand system correction. This includes enabling redress even for those indirectly harmed (e.g., via biased profiling). Ensure accessibility and transparency of the redress process, define timelines and escalation paths, and document how redress outcomes are used to improve system performance.
Interesting resources/references
Right to be treated fairly by a court (Universal Declaration of Human Rights), article 11 Freedom of expression and information, article 47 Right to an effective remedy and to a fair trial (Charter of fundamental rights of the European Union).
Could the system have an impact on decisions that affect life, health, or personal safety?
Consider for instance the risk if your AI system is used in the health sector for choosing the right treatment for a patient.
Is the output of the model accurate and fair?
Are your datasets representative enough and free from bias?
Does the system produce outputs, such as fake news, that could put the life of somebody in danger?
Could the system encourage harmful health practices or medical misinformation?
Also consider whether the system could lead to loss of human lives or a significant decline in quality of life, especially when used in safety-critical or decision-support contexts.
If your answer is Yes or MAYBE, you might be at risk
FLIPCARD
Recommendations
Design the system with rigorous safety standards to minimize risks in scenarios affecting the right to life, such as healthcare or emergency response. Ensure datasets are representative and regularly validated for fairness, accuracy, and absence of harmful biases.
Include safeguards against outputs that may promote harmful practices, misinformation, or decisions endangering life. Conduct robust testing to identify and mitigate potential errors or unintended consequences.
Prohibit the dissemination of outputs that could incite violence, endanger health, or spread medical misinformation. Establish a monitoring mechanism to flag and rectify such outputs in real-time.
Engage domain experts, such as healthcare professionals or ethics specialists, in the system design and evaluation process. Use their input to ensure the AI system aligns with ethical standards for protecting life.
Establish a post-market monitoring system to identify and address risks that may emerge after deployment, especially in dynamic contexts like healthcare or public safety.
Provide training for users and operators to ensure they understand the system's limitations and ethical implications, particularly in life-critical decision-making contexts. Encourage informed and responsible use through comprehensive documentation and guidelines.
Create mechanisms for users and affected individuals to challenge decisions that may impact the right to life. Implement a robust redressal process to address grievances and prevent recurrence of harmful outcomes.
Interesting resources/references
Right to life, No torture and inhuman treatment (Universal Declaration of Human Rights), article 2 Right to life, article 3 Right to the integrity of the person, article 4 Prohibition of torture and inhuman or degrading treatment or punishment (Charter of fundamental rights of the European Union).
Could the AI system limit, suppress or distort users’ freedom of expression?
Consider whether your AI system’s moderation, recommendation, or censorship mechanisms may inadvertently restrict or distort users' ability to express themselves freely.
If your answer is Yes or MAYBE, you might be at risk
FLIPCARD
Recommendations
Adhere to ethical guidelines and ensure transparency and accountability.
Regularly audit and refine content moderation algorithms to minimize false positives in detecting harmful content. Incorporate diverse training data that reflects a wide range of cultural, linguistic, and contextual nuances.
Provide users with clear explanations and opportunities to contest or appeal content moderation decisions. Develop an independent oversight committee to review contentious cases of content removal.
Collaborate with diverse stakeholders to ensure freedom of expression is preserved. Test the system with input from underrepresented communities to identify potential biases or oversights.
Allow users to customize their interaction with content filters, such as by adjusting sensitivity levels or choosing topics they wish to see moderated differently. Provide clear guidelines and options for users to express themselves within platform policies.
Establish mechanisms for users to report errors in content moderation and provide constructive feedback.
Continuously monitor the system's performance and adapt to emerging risks or contexts that may affect freedom of expression.
Align the system’s operation with international standards protecting freedom of expression, such as article 11 of the Charter of Fundamental Rights of the European Union and article 19 of the Universal Declaration of Human Rights.
Could our AI system affect access to services such as healthcare, housing, insurance, benefits or education?
The output of your model could be used to deny access to certain fundamental rights.
How can you be sure that the decisions of your AI system are always fair and correct?
How can you prevent causing harm to individuals?
AI systems intended to be used to determine access or admission, evaluate learning outcomes, or monitor students’ behaviors are classified as “high risk” by the AI Act (Annex III).
Could the AI system create barriers to healthcare access for some groups or individuals?
If your answer is Yes or MAYBE, you might be at risk
FLIPCARD
Recommendations
Adhere to EU Trustworthy AI guidelines to ensure fairness and accountability
Use diverse, representative training data to reduce biases that could disproportionately impact certain groups.
Regularly audit the system for unintended discriminatory effects and address identified issues.
Provide clear explanations for decisions made by the AI system, including the data and logic used. Allow users to challenge decisions and request human reviews.
Establish post-market monitoring processes to detect and address issues that arise after deployment.
Update the system regularly to account for changes in legal requirements, societal norms, and data quality. For high-risk applications, such as determining healthcare access or evaluating job candidates, establish stringent safeguards to minimize the risk of harm. Implement thresholds and fail-safes to ensure critical decisions are accurate, fair, and reliable.
Work with regulatory bodies, civil society organizations, and industry peers to establish best practices and promote fairness and equity in AI systems. Ensure the AI system is designed to accommodate a wide range of users, including those with varying needs and abilities. Regularly test the system in diverse real-world settings to validate its accessibility and fairness. Use stakeholder consultations to understand the specific needs and vulnerabilities of affected groups.
Interesting resources/references
Right to education, Right of social service (Universal Declaration of Human Rights), article 14 Right to education, article 34 Social security and social assistance, article 35 Healthcare, article 36 Access to services of general economic interest (Charter of fundamental rights of the European Union)
Could the AI system interfere with users’ autonomy influencing their decision-making process?
Could your system affect which choices and which information is made available to people?
Could the AI system affect human autonomy by generating over-reliance by users (too much trust on the technology)?
Could this reinforce their beliefs or encourage certain behaviors?
Could the AI system create human attachment, stimulate addictive behavior, or manipulate user behavior?
Could the AI system mislead consumers or provide false recommendations?
If your answer is Yes or MAYBE, you might be at risk
FLIPCARD
Recommendations
Clearly explain how the AI system processes inputs and generates outputs to avoid unintentional manipulation or misrepresentation. Ensure users understand the limitations and intended purposes of the AI system through user-friendly documentation and communication. Offer features that allow users to adjust or override AI recommendations, ensuring they maintain control over decisions. Implement mechanisms for users to pause, disable, or opt-out of certain AI functionalities.
Implement safeguards to detect and reduce over-reliance, such as reminders or notifications encouraging users to seek alternative opinions or double-check recommendations. Include disclaimers or warnings about the system’s limitations in contexts where over-reliance might occur.
Refrain from using techniques that exploit psychological vulnerabilities, such as gamification, excessive notifications, or reward loops that could encourage addictive behavior. Periodically evaluate whether design elements unintentionally foster dependency on the system.
Test the system with users from various cultural, socioeconomic, and demographic backgrounds to understand potential impacts on different groups. Incorporate diverse perspectives to avoid inadvertent biases that could restrict autonomy for certain populations.
Continuously monitor for any behaviors or outputs that may interfere with user decision-making processes. Use post-market monitoring to collect feedback and implement updates to reduce unintended autonomy infringements. Ensure human oversight mechanisms are in place for critical decision-making areas. Clearly define the role of the AI system as a tool to assist, not replace, human decision-making.
Interesting resources/references
Article 6 Right to liberty and security, article 3 Right to the integrity of the person, article 38 Consumer protection (Charter of fundamental rights of the European Union), article 5a (AI Act)
Could the AI system promote certain values or beliefs on users?
Could cultural and language differences be an issue when it comes to the ethical nuance of your algorithm? Well-meaning values can create unintended consequences.
Must the AI system understand the world in all its different contexts?
Could ambiguity in rules you teach the AI system be a problem?
Can your system interact equitably with users from different cultures and with different abilities?
If your answer is Yes or MAYBE, you might be at risk
FLIPCARD
Recommendations
Consider designing with value alignment, which means that you want to ensure consideration of existing values and sensitivity to a wide range of cultural norms and values.
Make sure that when you test the product you include a large diversity in type of users.
Think carefully about what diversity means in the context where the product is going to be used.
Remember that this is a team effort and not an individual decision.
Interesting resources/references
Freedom of thought and religion(Universal Declaration of Human Rights), article 22 Cultural, religious and linguistic diversity, article 10 Freedom of thought, Conscience and religion (Charter of fundamental rights of the European Union)
Could the AI system negatively impact vulnerable groups or fail to protect their rights?
AI systems can unintentionally marginalize or harm vulnerable individuals or groups, such as children, the elderly, migrants, ethnic minorities, or individuals with cognitive or psychosocial disabilities.
These groups often face barriers to representation, consent, and redress. AI systems may reflect or amplify societal biases, particularly if training data lacks diversity or design decisions fail to account for structural inequalities.
The EU Charter of Fundamental Rights and the AI Act emphasize special protection for vulnerable populations, especially where AI is deployed in high-risk domains like education, health, welfare, or justice.
If your answer is Yes or MAYBE, you might be at risk
FLIPCARD
Recommendations
Conduct a Human Rights Impact Assessment (HRIA) early in the design process, paying special attention to risks of exclusion, discrimination, or harm to vulnerable populations.
Engage with advocacy organizations, domain experts, and affected groups to surface risks that may not be visible from a technical perspective.
Ensure that training data includes diverse representations and that the system can adapt to variations in user ability, language, culture, or socioeconomic background.
Include clear channels for recourse, appeal, and human oversight, especially for automated decisions that significantly affect individuals.
Review deployment contexts for hidden power asymmetries or coercion risks, particularly where vulnerable groups may be subject to profiling or behavioral nudging.
Could the AI system fail to uphold the rights and best interests of children?
Children interacting with AI systems require special protections to ensure their rights, safety, and well-being are preserved. AI systems used by or designed for children must prioritize their best interests, such as ensuring age-appropriate content, safeguarding their privacy, and fostering their ability to share, learn, and express themselves freely. A failure to address these factors could result in harm, exploitation, or the suppression of their rights. For example, an AI system might expose children to inappropriate content, fail to protect their personal data, or limit their ability to engage in meaningful learning and expression.
If your answer is Yes or MAYBE, you might be at risk
FLIPCARD
Recommendations
Develop and test the system for age-appropriateness.
Implement mechanisms to filter and block harmful or inappropriate content.
Adhere to strict data privacy regulations, such as GDPR, ensuring children’s data is protected. Foster safe environments where children can freely share their thoughts and ideas. Include features that support interactive and meaningful learning experiences.
Engage with experts in child development, education, and rights advocacy during the design phase. Consult children (where appropriate) to ensure their perspectives are respected and integrated.
Continuously monitor the AI system for unintended harms or risks to children.
Clearly communicate to parents, guardians, and educators how the AI system works and the measures in place to protect children. Provide accessible guidelines for safe and effective use.
Interesting resources/references
Article 24 The rights of the child (Charter of Fundamental Rights of the European Union)
Is the development and use of the AI system proportionate to its intended purpose and impact on rights?
Proportionality is a general principle of EU law. It requires you to strike a balance between the means used and the intended aim.
In the context of fundamental rights, proportionality is key for any limitation on these rights.
If your answer is No or MAYBE, you might be at risk
FLIPCARD
Recommendations
Proportionality requires that advantages due to limiting the right are not outweighed by the disadvantages to exercise the right. In other words, the limitation on the right must be justified.
Safeguards accompanying a measure can support the justification of a measure. A pre-condition is that the measure is adequate to achieve the envisaged objective.
In addition, when assessing the processing of personal data, proportionality requires that only that personal data which is adequate and relevant for the purposes of the processing is collected and processed. Source: EDPS
Does the AI system use behavioral data in ways that may raise ethical, privacy, or human rights concerns?
Behavioral data includes individuals' actions, habits, preferences, or biometric responses, such as keystrokes, browsing history, device usage, or emotional expressions.
AI systems that track and learn from behavior can create serious risks, such as:
Privacy violations through covert or unconsented surveillance.
Profiling and discrimination, as behavioral traits may act as proxies for protected characteristics (e.g., gender, ethnicity, age).
Manipulation and behavioral exploitation, especially if labeling or feedback loops reinforce conformity or nudge users toward certain actions.
Chilling effects on autonomy and expression, particularly in politically sensitive or authoritarian contexts.
These risks implicate key rights under the EU Charter of Fundamental Rights, the ECHR, and the EU AI Act, which designates behavior-influencing AI as high-risk.
If your answer is Yes or MAYBE, you might be at risk
FLIPCARD
Recommendations
Define and document how behavioral data is collected, labeled, and used, including value judgments behind 'positive' or 'negative' classifications.
Obtain explicit, informed consent for behavior tracking and provide opt-out mechanisms.
Implement privacy-preserving techniques (e.g., differential privacy, federated learning) to reduce data exposure.
Regularly audit for bias in behavior-based profiling and assess the representativeness and fairness of training data.
Conduct Human/Fundamental Rights Impact Assessments or DPIAs where applicable.
Apply safeguards to prevent misuse in sensitive domains (e.g., employment, finance, public services), and assess whether the system qualifies as high-risk under the EU AI Act.
Interesting resources/references
Article 1, Human dignity, article 7 Right to privacy, article 10 Freedom of thought, conscience, and religion (Charter of Fundamental Rights of the European Union)
Is the AI system's task clearly defined, with well-scoped objectives and boundaries?
Is the problem you want to solve well defined? Are the system's goals specific and measurable?
Are the possible benefits clear and aligned with the intended use?
Clearly defining the AI system’s task and intended purpose helps set boundaries for design, training, deployment, and oversight.
A vague or evolving objective may lead to scope creep, misaligned optimization, or unintended consequences. This is especially critical in high-risk use cases where safety, fairness, or legal compliance are required.
The intended purpose must also be documented and traceable throughout the lifecycle, this is essential for risk classification, legal accountability, and effective stakeholder communication (e.g., users, regulators, auditors).
If your answer is No or MAYBE, you might be at risk
FLIPCARD
Recommendations
Clearly define the problem and outcome you are optimizing for.
Assess if your AI system will be well-suited for this purpose.
Always discuss if there are alternative ways to solve the problem.
Define success. Working with individuals who may be directly affected can help you identify an appropriate way to measure success.
Make sure there is a stakeholder involved (product owner for instance) with enough knowledge of the business and a clear vision about what the model needs to do.
Have you considered using analytics first? In this context analytics could also offer inspiring views that can help you decide on the next steps. They can be a good source of information and are sometimes enough to solve the problem without the need of AI/ML.
Have we identified and involved all key stakeholders relevant to this phase of the AI lifecycle?
Do you have all the necessary stakeholders on board? Not having the right people that can give the necessary input can put the design of the AI system in danger.
Think for instance when attributes or variables need to be selected, or when you need to understand the different data contexts.
Data scientists should not be the only ones making assumptions about variables, it should really be a team effort.
If your answer is No or MAYBE, you might be at risk
FLIPCARD
Recommendations
Identify and involve relevant stakeholders early in the AI system lifecycle. This will avoid unnecessary rework and frustrations.
Identifying who is responsible for making the decisions and how much control they have over the decision-making process allows for a more evident tracking of responsibility in the AI’s development process.
Training and Oversight Readiness
Have all relevant staff and users received adequate training to understand, oversee, and responsibly interact with the AI system?
Individuals involved in the development, deployment, operation, or use of AI systems must understand their functionality, risks, and limitations. Without adequate training, staff may misuse the system, fail to detect errors, or be unable to intervene effectively. This undermines human oversight, accountability, and compliance with regulatory requirements. Article 4 of the EU AI Act emphasizes the need for AI literacy, particularly for those responsible for high-risk systems.
If your answer is No or MAYBE, you might be at risk
FLIPCARD
Recommendations
Provide structured, role-specific training for developers, operators, decision-makers, and users interacting with the AI system.
Cover system capabilities, limitations, error detection, appropriate interventions, and escalation procedures.
Include modules on fairness, data protection, explainability, and responsible interpretation of AI outputs.
Refresh training regularly to reflect system updates and evolving regulations.
Track and document training participation as part of accountability measures.
Integrate training into onboarding and ongoing professional development frameworks.
Interesting resources/references
Article 4 EU AI Act: I Literacy
AI Agents’ Feedback
Do we have qualified people available to supervise the behavior of AI agents and provide feedback during learning?
Reinforcement Learning (RL) is an area of machine learning concerned with how intelligent agents ought to take actions in an environment in order to maximize the notion of cumulative reward. Source: Wikipedia
When the agent is learning to perform a complex task, human oversight and feedback are more helpful than just rewards from the environment. Rewards are generally modelled such that they convey to what extent the task was completed, but they do not usually provide sufficient feedback about the safety implications of the agent’s actions. Even if the agent completes the task successfully, it may not be able to infer the side-effects of its actions from the rewards alone. In the ideal setting, a human would provide fine-grained supervision and feedback every time the agent performs an action (Scalable oversight). Though this would provide a much more informative view about the environment to the agent, such a strategy would require far too much time and effort from the human.
If your answer is No or MAYBE, you might be at risk
FLIPCARD
Recommendations
One promising research direction to tackle this problem is semi-supervised learning, where the agent is still evaluated on all the actions (or tasks), but receives rewards only for a small sample of those actions.
Another promising research direction is hierarchical reinforcement learning, where a hierarchy is established between different learning agents. There could be a supervisor agent/robot whose task is to assign some work to another agent/robot and provide it with feedback and rewards.
Do we have the resources and processes to effectively oversee AI decision-making?
Human oversight is essential for identifying errors, biases, or unintended consequences in AI systems, especially in high-risk contexts. However, meaningful oversight requires not only a procedural mechanism but also adequate staffing, expertise, training, and organizational support.
Without sufficient resources, human reviewers may merely rubber-stamp decisions or fall into automation bias, reducing accountability and increasing the likelihood of harmful outcomes.
If your answer is No or MAYBE, you might be at risk
FLIPCARD
Recommendations
Allocate clear roles and responsibilities for oversight.
Train reviewers to recognize automation bias and understand the system's limitations.
Establish workflows that support human-in-the-loop or human-on-the-loop oversight.
Involve multidisciplinary stakeholders in the review process to ensure meaningful checks and balances.
Have we defined who is accountable for the AI system’s decisions and outcomes?
AI outputs can lead to mistakes or even cause harm. In such cases, is it clear who is responsible within your organization? Are accountability structures clearly defined and documented?
If your answer is No or MAYBE, you might be at risk
FLIPCARD
Recommendations
Assign and communicate responsibilities for AI decision-making, considering both legal and ethical accountability.
Use decision logs and role-based access control to document and track accountability throughout the AI system’s lifecycle.
Get leadership involved in maintaining oversight, keeping accountability a priority at all levels.
Do we regularly review whether the AI system’s goals, assumptions, and impacts are still appropriate?
AI models and their objectives may drift from their original intent, making human oversight crucial to ensure ongoing alignment with ethical and business objectives. Are there periodic human-led reviews in place to monitor AI system behavior, validate outcomes, and reassess goals? Human oversight should play an active role in detecting unintended consequences, adjusting governance policies, and maintaining accountability throughout the AI system’s lifecycle.
If your answer is No or MAYBE, you might be at risk
FLIPCARD
Recommendations
Schedule regular reassessments of AI objectives and assumptions.
Update training data, governance policies, and oversight structures as AI systems evolve.
Can human operators safely interrupt or override the AI system at any time?
High-risk AI systems must provide natural persons with the means to stop or override the system when necessary. This includes mechanisms such as a 'stop button' or fallback procedures that bring the system to a safe state.
A lack of override capabilities could lead to harm, especially in autonomous systems where malfunction or misalignment may go unnoticed without human intervention.
If your answer is No or MAYBE, you might be at risk
FLIPCARD
Recommendations
Design systems with built-in override or halt capabilities.
Ensure that these mechanisms are tested regularly and accessible to responsible personnel.
Document override procedures clearly and provide training to relevant users.
Could users contest or challenge the decisions made by the AI system?
Some AI systems make or support decisions that significantly affect individuals, such as in hiring, lending, or criminal justice. If users cannot challenge these decisions or request human review, the system may violate oversight obligations and erode trust. Lack of contestability undermines accountability and may breach Article 22(3) of the GDPR or Article 14 of the EU AI Act, both of which require mechanisms for human intervention and review.
If your answer is No or MAYBE, you might be at risk
FLIPCARD
Recommendations
Ensure the AI system includes mechanisms for contestability, allowing users to challenge or seek review of decisions that negatively impact them. Wrong decisions could also have an impact on people that have not been the target of the data collection (data spillovers).
Provide clear instructions on how users can initiate such challenges and ensure that this process is transparent, accessible, and user-friendly.
Incorporate features that enable human oversight in decision-making processes, ensuring users have the option to escalate issues to human operators.
Establish a redressal process that includes timelines for resolution, a clear escalation hierarchy, and mechanisms for feedback integration to improve the system’s decision-making over time.
Regularly audit and evaluate the decision-making outcomes of the AI system, focusing on areas where users frequently raise disputes. Use these audits to improve system accuracy and reduce the need for contestation.
Provide detailed and comprehensible explanations of the system’s outputs to users, ensuring they understand how decisions are made and what data was used.
Engage relevant stakeholders, including legal experts, ethicists, and representatives from affected user groups to design and evaluate the contestability mechanisms and ensure they meet ethical and regulatory standards.
Train system operators and customer support staff to handle disputes arising from the AI system effectively, ensuring they are equipped to assist users in navigating the contestation process.
Right to be treated fairly by a court (Universal Declaration of Human Rights), article 11 Freedom of expression and information, article 47 Right to an effective remedy and to a fair trial (Charter of fundamental rights of the European Union).
Have we assessed our legal liability for damages caused by our AI system?
Failing to assess liability risks can expose your organization to legal, financial, and reputational damage.
Have you identified who could be held liable, your organization, end-users, third parties?
Black-box AI systems complicate the attribution of responsibility, especially in high-risk or harmful scenarios, increasing the burden of proof for affected individuals.
Legal liability varies across jurisdictions, and evolving regulations such as the EU AI Liability Directive may significantly affect your obligations.
Failure to document decision-making processes and ensure auditability can weaken your defense in case of litigation.
If your answer is No or MAYBE, you might be at risk
FLIPCARD
Recommendations
Conduct a liability risk assessment for your AI system, including mapping potential damages and responsible parties.
Implement transparency, traceability, and auditability mechanisms throughout the AI lifecycle to support accountability.
Ensure that risk scenarios are documented and, where relevant, covered by insurance policies.
Stay informed about legal developments in AI liability.
Provide training to relevant teams on legal accountability and AI governance best practices.
Do we have adequate resources and MLOps practices in place to manage, monitor, and maintain our AI system?
MLOps (Machine Learning Operations) refers to the engineering and governance practices required to reliably develop, deploy, and monitor machine learning models in production. Without proper MLOps, organizations may face:
Model Drift: Performance degradation due to changes in input data or real-world conditions.
Lack of Traceability: Difficulty reproducing results or auditing decisions.
Operational Failures: Models failing silently or behaving unpredictably in production.
Compliance Risks: Inability to demonstrate accountability or meet regulatory requirements.
MLOps is especially important for high-risk AI applications under the EU AI Act, where continuous monitoring, retraining, and documentation are legal obligations.
If your answer is No or MAYBE, you might be at risk
FLIPCARD
Recommendations
Establish clear MLOps processes including versioning, CI/CD pipelines, and model registry.
Continuously monitor model performance, fairness, and drift.
Ensure auditability by logging predictions, training runs, and data lineage.
Automate testing and rollback mechanisms for safe model updates.
Define clear responsibilities between data scientists, ML engineers, and operations staff.
Include human-in-the-loop checks or alerts for sensitive or safety-critical applications.
If we plan to deploy a third-party AI tool, have we assessed our shared responsibility for its potential impact on users?
If you use a third-party tool you might still have a responsibility towards the users. Think about employees, job applicants, patients, etc. It is also your responsibility to make sure that the AI system you choose won't cause harm to the individuals.
If your answer is No or MAYBE, you might be at risk
FLIPCARD
Recommendations
If personal data is involved, review which ones are your responsibilities (look into art. 24 and 28 GDPR).
You can also start by checking:
That you have the right agreements in place with the third party provider.
That the origin and data lineage of their datasets are verified.
How their models are fed; do they anonymize the data?
How you have assessed their security, ethical data handling, quality processes and measures to prevent bias and discrimination in their AI system.